





- A Data-driven Multiscale Analysis forHyperelastic Composite Materials Based on the Mean-field Homogenization Method
Suhan Kim*, Wonjoo Lee*, Hyunseong Shin*†
* Department of Mechanical Engineering, Inha University, Incheon 22212, Korea
- 초탄성 복합재의 평균장 균질화 데이터 기반 멀티스케일 해석
김수한*· 이원주*· 신현성*†
This article is an open access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
The classical multiscale finite element (FE2) method involves iterative calculations of micro-boundary value problems for representative volume elements at every integration point in macro scale, making it a computationally time and data storage space. To overcome this, we developed the data-driven multiscale analysis method based on the mean-field homogenization (MFH). Data-driven computational mechanics (DDCM) analysis is a model-free approach that directly utilizes strain-stress datasets. For performing multiscale analysis, we efficiently construct a strain-stress database for the microstructure of composite materials using mean-field homogenization and conduct data-driven computational mechanics simulations based on this database. In this paper, we apply the developed multiscale analysis framework to an example, confirming the results of data-driven computational mechanics simulations considering the microstructure of a hyperelastic composite material. Therefore, the application of data-driven computational mechanics approach in multiscale analysis can be applied to various materials and structures, opening up new possibilities for multiscale analysis research and applications
기존의 멀티스케일 유한요소법(Multiscale finite element, FE2)은 거시 스케일의 모든 적분점에서 대표 체적 요소(representative volume element, RVE)의 미시 경계치 문제를 반복적으로 계산하기 때문에 긴 해석 시간과 많은 데이터 저장 공간을 필요로 한다. 이를 해결하기 위해 본 연구에서 평균장 균질화 데이터 기반 멀티스케일 해석기법을 개발하였다. 데이터 기반 전산역학(data-driven computational mechanics, DDCM) 해석은 변형률-응력 데이터 셋을 직접적으로 사용하는 모델-프리(model-free)접근 방식이다. 멀티스케일 해석을 수행하기 위해, 평균장 균질화(mean-field homogenization)를 활용하여 복합재의 미세구조에 대한 변형률-응력 데이터베이스(database)를 효율적으로 구축하고, 이를 기반으로 데이터 기반 전산역학 시뮬레이션을 수행하였다. 본 논문에서는 개발한 멀티스케일 해석 프레임워크(framework)를 예제에 적용하여, 초탄성(hyperelasticity) 복합재의 미세 구조를 고려한 데이터 기반 전산역학 시뮬레이션 결과를 확인하였다. 따라서, 데이터 기반 전산역학 접근 방식을 활용한 멀티스케일 해석기법은 다양한 재료 및 구조에 적용될 수 있으며, 멀티스케일 해석 연구 및 응용 가능성을 열어줄 것으로 기대된다.
Keywords: 데이터 기반 전산 역학(Data-driven computational mechanics), 멀티스케일 해석(Multiscale analysis), 평균장 균질화(Mean-field homogenization), 초탄성(Hyperelasticity)
다양한 스케일에서의 멀티스케일 이론과 모델링을 기반으로 비선형 재료에 대한 균질화 해석 방법이 개발되어 왔다[1-8]. 그중 멀티스케일 유한요소(multiscale finite element, FE2) 해석은 미시 스케일과 거시 스케일의 경계치 문제를 함께 고려하는 유한요소 기반의 해석 방법이다[9]. 기존의 FE2 방법은 거시 스케일의 경계치 문제를 해결하기 위해, 매 스텝마다 거시 스케일 유한요소 모델의 모든 적분점에서 대표 체적 요소(representative volume element, RVE)에 대한 균질화 해석을 수행해야 한다. 따라서, 상당히 많은 해석 시간과 데이터 저장 공간을 필요로 하게 된다. 이러한 FE2의 효율성을 향상시키기 위해 적합직교분해기법[10-12]과 인공신경망[13,14] 등의 방법을 활용한 연구들이 활발하게 진행되고 있다. 그러나, 여전히 FE2 해석은 계산 시간이 많이 소요되거나 어느 정도의 정확도를 포기해야 하는 부담이 있다. 이러한 문제를 대처하기 위해 가장 효과적인 접근 방식 중 하나로 거시 문제와 미시 문제의 분리(decoupling)에 대한 필요성이 제기되고 있다[15]. 따라서, 계산 효율성을 향상시키기 위해서는 거시 스케일에서의 경계치 문제와 미시 스케일에서의 경계치 문제를 독립적으로 해결할 필요가 있고, 새로운 패러다임의 전산역학 기술이 요구되고 있다.
데이터 기반 전산역학(data-driven computational mechanics, DDCM) [16-22]은 컴퓨팅 패러다임의 중요한 기술 중 하나로 주목받고 있다. DDCM은 미리 대량의 변형률-응력 데이터베이스를 구축하고, 이를 활용하여 거시 경계치 문제의 평형방정식과 적합방정식을 가장 잘 만족하는 데이터를 선택하여 모든 적분점에 매핑(mapping)하는 해석
시뮬레이션 기술이다. Hu는 데이터 기반 시뮬레이션을 활용하여, 유한요소 균질화 데이터베이스를 이용한 데이터 기반 멀티스케일 유한요소(data-driven FE2) 방법을 개발하였다[15]. 거시와 미시 경계치 문제를 동시에 해결할 필요없이 미시적 오프라인 컴퓨팅(microscopic offline computing)과 거시적 온라인 컴퓨팅(macroscopic online computing) 과정을 각각 수행함으로써 데이터 기반 멀티스케일 해석을 구현할 수 있음을 확인하였다. 또한, 비교적 높은 계산 효율성과 정확성을 보여주었으며, 이를 통해 기존의 FE2 기법과 비교하여 개선되었다는 결론이 보고되었다. 그러나 미시적 오프라인 컴퓨팅 과정에서 사전 정보(prior information) 없이 유한요소 균질화 데이터베이스를 방대하게 생성하는 것은 효율적이지 않으며, 여전히 연구되어야 할 부분으로 남아있다.
본 연구에서는 평균장 균질화(mean-field homogenization) 기법을 사용하여 변형률-응력 데이터베이스를 효율적으로 구축하고, 이를 활용한 데이터 기반 멀티스케일 해석을 수행하고자 한다. 균질화 데이터베이스를 구축하기 위한 방법으로, 대표 체적 요소에 대한 유한요소 기반 균질화 작업은 시간이 많이 소요되는 단점이 있다. 그러나 평균장 균질화 기법[23-25]은 강화재를 포함하는 복합재의 기계적 물성을 효율적으로 예측하는 방법으로 알려져 있으며, 특히 체적분율이 낮은 복합재료에 대해서는 높은 정확성을 보이고 있다. 본 논문에서는 초탄성 복합재에 대해 평균장 균질화 기법을 적용하여 데이터베이스를 효율적으로 생성하고, 균질화 데이터베이스를 토대로 데이터 기반 전산역학 시뮬레이션을 수행하여 결과를 확인하였다. 최종적으로, 데이터 기반 멀티스케일 프레임워크는 FE2 효율을 보다 증가시켜 다양한 복합재료 및 구조 시스템을 해석하기 위한 기술로 발전할 것으로 기대된다.
2.1 평균장 균질화
본 연구에서는 Mori-Tanaka (M-T) 방법을 활용하여 복합재의 유효 재료 거동을 도출하였다. 구체적으로, 주어진 거시 변형률 E에 대해, 거시 응력 Σ를 계산하였으며, 본 연구에서 사용한 초탄성 복합재에 대한 균질화 이론은 참고문헌에 자세하게 소개되어 있다[25].
초탄성 거동 모사를 위한 재료 모델로 무니리블린 모델(Mooney-Rivlin model)을 사용하였다. 초탄성 재료 모델은 변형률 에너지 밀도를 변형 구배 텐서를 이용하여 스칼라 함수로 표현된다. 변형 구배 텐서는 주 신장률(principle stretch)에 의한 불변량(invariant)을 활용하여 표현이 가능하다. 변형률 에너지 밀도 W 식은 다음과 같다.
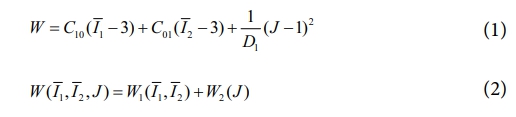
무니리블린 모델은 W1인 왜곡(distortion) 변형 에너지 밀도와 W2인 체적(volumetric) 변형 에너지밀도로 이루어져 압축성 모델로 사용할 수 있다. 여기서 Ι̅1, Ι̅2, J는 주 신장률에 의한 불변량을 나타낸다. 재료 물성인 C10, C01은 전단 계수, D1은 체적 탄성 계수의 의미로 표현된다. D1이 0인 경우 비압축성 재료로 간주할 수 있다.
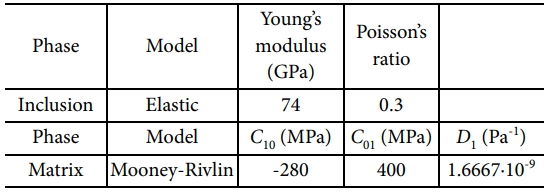
복합재의 모재(matrix)는 초탄성 재료를, 첨가재(inclusion)는 탄성 재료로 구성하였다. DIGIMAT software는 첨가재의 체적비, 방향, 형상 등의 변수를 고려하고, 평균장 균질화를 활용하여 복합재료의 등가 물성을 계산함으로써 복합재료의 거동을 파악할 수 있다. 이를 통해, 미세 구조의 물성을 기반으로 하여 복합 재료의 거시적 성능을 빠르게 예측할 수 있었다.
2.2 데이터 기반 전산 역학
거리 최소화 알고리즘 기반 데이터 기반 전산 역학(data-driven computational mechanics, DDCM)은 해석적 함수 형태의 구성방정식을 활용하지 않고, 변형률-응력 데이터 베이스를 직접적으로 사용하는 역학적 해석 방법이다[16]. 이 방법은 이산적인 응력과 변형률 데이터 중, 거시 구조의 적합 방정식과 평형 방정식을 가장 잘 만족하는 데이터를 찾는 최적화 알고리즘에 기반한다. 여기서, 거리 최소화 알고리즘은 데이터 셋 내에서 특정한 제약 조건 또는 목표를 고려하여 거리를 최적화하기 위한 솔루션을 찾는 것을 목표로 한다[16-22,26,27]. 본 연구에서는 DDCM 기법을 거시 경계치 문제 해석에 사용하였고, 그 과정에서 해석적 함수에 기반한 구성방정식 모델링 없이, 재료 거동 데이터베이스를 직접적으로 사용하였다. 이러한 접근을 통해, 재료 거동의 해석적 함수 기반의 모델링으로 인한 오류를 줄일 수 있었다.
다음과 같은 전역적인 페널티 함수 φ를 통해 데이터베이스 D 내에서 가장 적합한 변형률-응력 데이터를 선택하였다. 적합방정식 및 평형 방정식의 제약조건 셋(E, Σ)과 데이터 셋(E′, Σ′) 사이의 거리 최소화 문제를 다음과 같이 공식화할 수 있다.
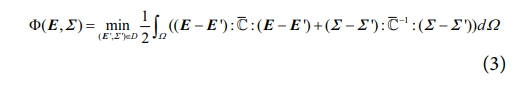
여기서 Ω는 거시적 영역이고 C̅는 변형률-응력 공간의 거리를 정의하기 위해 도입된 텐서이다. 데이터베이스 D 내에 있는 변형률-응력 데이터 중에서, 제약조건 셋과 가장 가까운 데이터를 식 (3)을 이용하여 거리 최소화 문제를 계산하고, 이를 통해 적절한 데이터 셋을 찾아가도록 한다. 즉, 거리 최소화 알고리즘 기반 DDCM의 목적 함수는 적합방정식 및 평형방정식의 제약 조건을 만족시키면서 사전에 구축한 변형률-응력 데이터베이스 안에서 가장 적절한 변형률-응력 해를 찾는 것이다. 적합방정식과 평형방정식은 다음과 같이 표현할 수 있다.
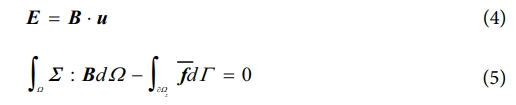
여기서 계수 B는 변형률-변위 관계를 나타내는 텐서이고, ∂ΩΣ는 하중 경계, f͞͞는 적용된 힘을 나타낸다. 적합방정식과 평형방정식을 제약 조건으로 부여하고, 이를 가장 잘 만족하는 변형률-응력 데이터를 찾기 위한 함수는 다음과 같이 정의할 수 있다.
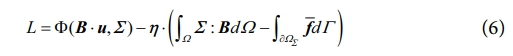
여기서 η는 라그랑주 승수이며, 편미분을 통해 다음과 같은 식을 유도할 수 있다.
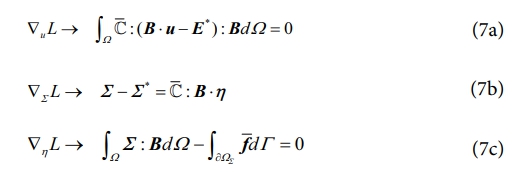
여기서 (E*, Σ*)는 거시 구조의 유한요소 적분점 별 최적 변형률-응력 해를 의미한다. 이 최적해는 다음과 같은 조건을 만족한다.
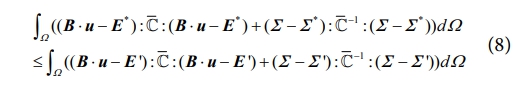
여기서 (E′, Σ′)는 데이터베이스 D에 존재하는 임의의 변형률-응력 데이터 포인트이다. 라그랑주 승수법을 통해 유도한 방정식은 다음과 같이 표현된다.
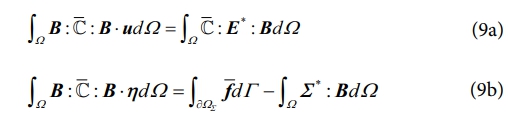
여기서 식 (9a)와 식 (9b)의 해인 k번째 스텝의 변위 u(k)와 라그랑주 승수 η(k)를 식 (4)와 식 (7b)에 대입하여 k번째 스텝의 변형률과 응력 집합(E(k), Σ(k))을 얻을 수 있다. 여기서 (E(k), Σ(k))는 반드시 사전에 구축한 데이터 베이스 D 내에 존재하는 변형률-응력 데이터 포인트는 아니며, 데이터 베이스 D 내에 있는 변형률-응력 데이터 중에, (E(k), Σ(k))에 가장 가까운 데이터를 계산하여, (E*(k+1), Σ*(k+1))로 정의한다. 이 과정을 변형률-응력 해가 수렴할 때까지 반복한다.
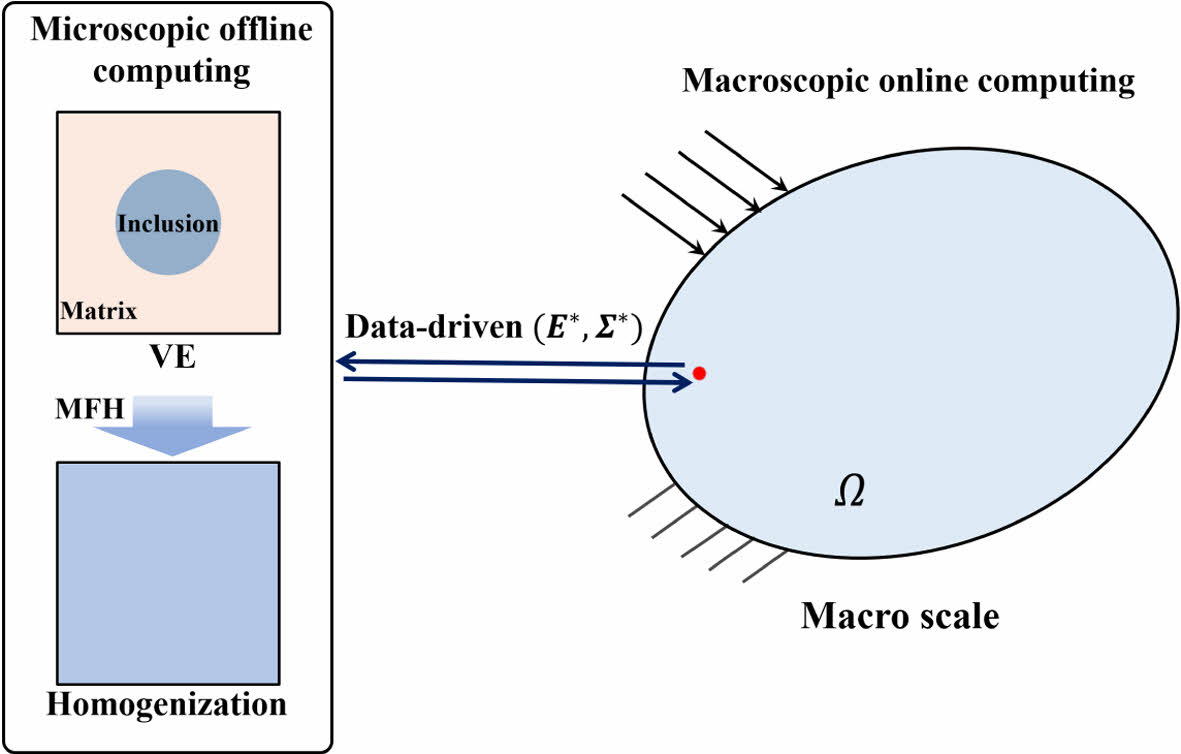
본 장에서는 Fig. 1과 같이, 평균장 균질화 이론을 활용하여 초탄성 복합재 데이터를 구축하고 데이터 기반 전산 역학 해석을 수행하였다. 데이터를 직접적으로 사용하여 유한요소를 풀어내기 위해서는 충분한 정확성 확보를 위해 많은 양의 데이터베이스가 필요로 한다. 해석적 함수 형태의 구성방정식 없이 변형률-응력 관계를 데이터베이스를 통해 대체하는 경우, 충분한 데이터가 없으면 해석에 오차가 크게 발생할 수 있다. 충분한 데이터베이스를 효율적으로 구축하기 위해, 평균장 균질화 이론을 적용하여 거시 거동 데이터베이스를 생성할 수 있었다.
강화재의 체적 분율은 0.2018로 가정하였으며, 복합재 구성성분의 물성은 Table 1에 기재하였습니다. 거시 변형률 범위는[-3∙10-2≤E11≤3∙10-2, -3∙10-2≤E22≤3∙10-2, -3∙10-2≤E12≤3∙10-2]로 평균장 균질화를 사용하여 각 변형률 범위 안에서 1250개의 변형률-응력 선도 데이터를 생성하여 데이터베이스를 구축하였다.
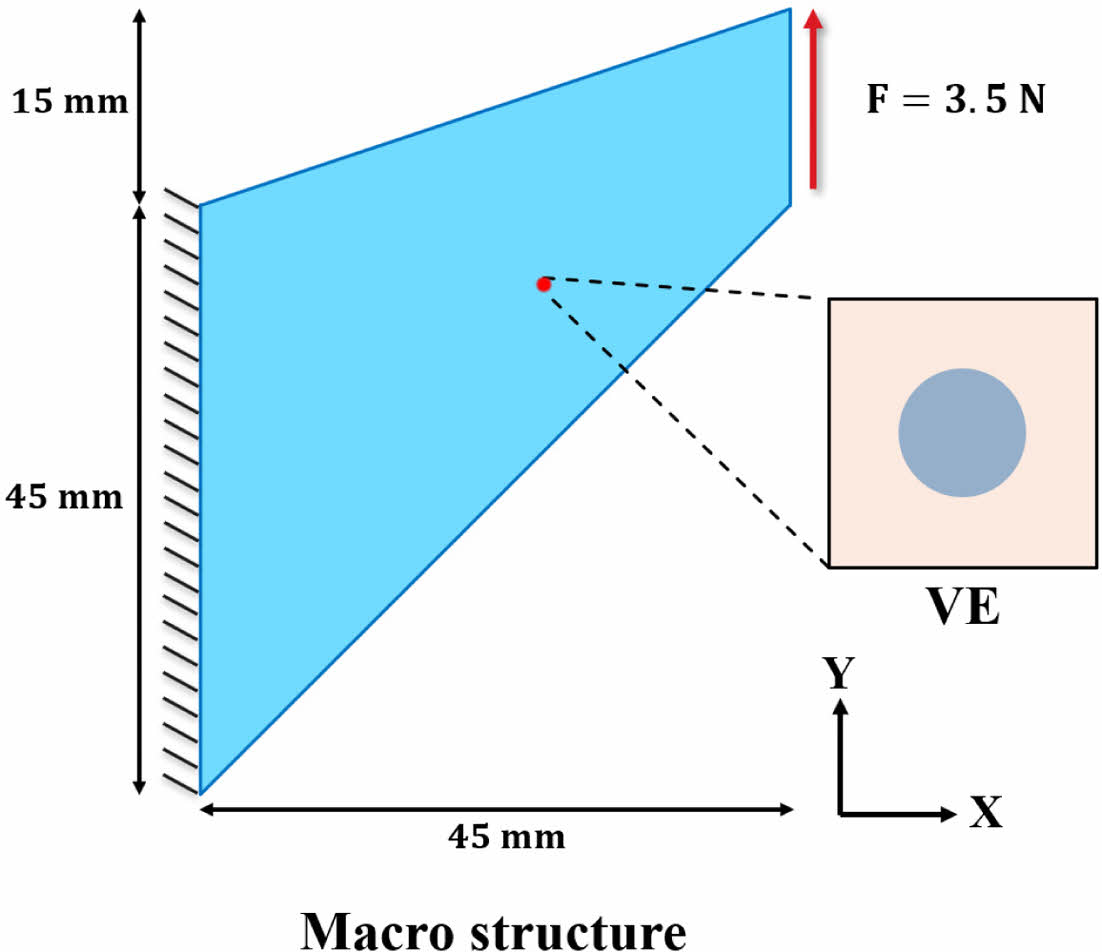
Fig. 2의 문제를 유한요소로 활용하여 풀기 위해, Fig. 3과 같이 1260개의 요소와 1333개의 노드로 이루어진 1 mm 두께의 2D 평면 변형률 유한요소 모델을 구성하였다. 왼쪽면을 고정하기 위한 변위경계조건을 부여하고 오른쪽 면에서는 Y축 방향으로 힘을 가하였다. 유한요소 모델링을 위해서 ABAQUS를 통해 4절점 하이브리드 선형 사각형 요소(CPE4H)를 사용하였다.
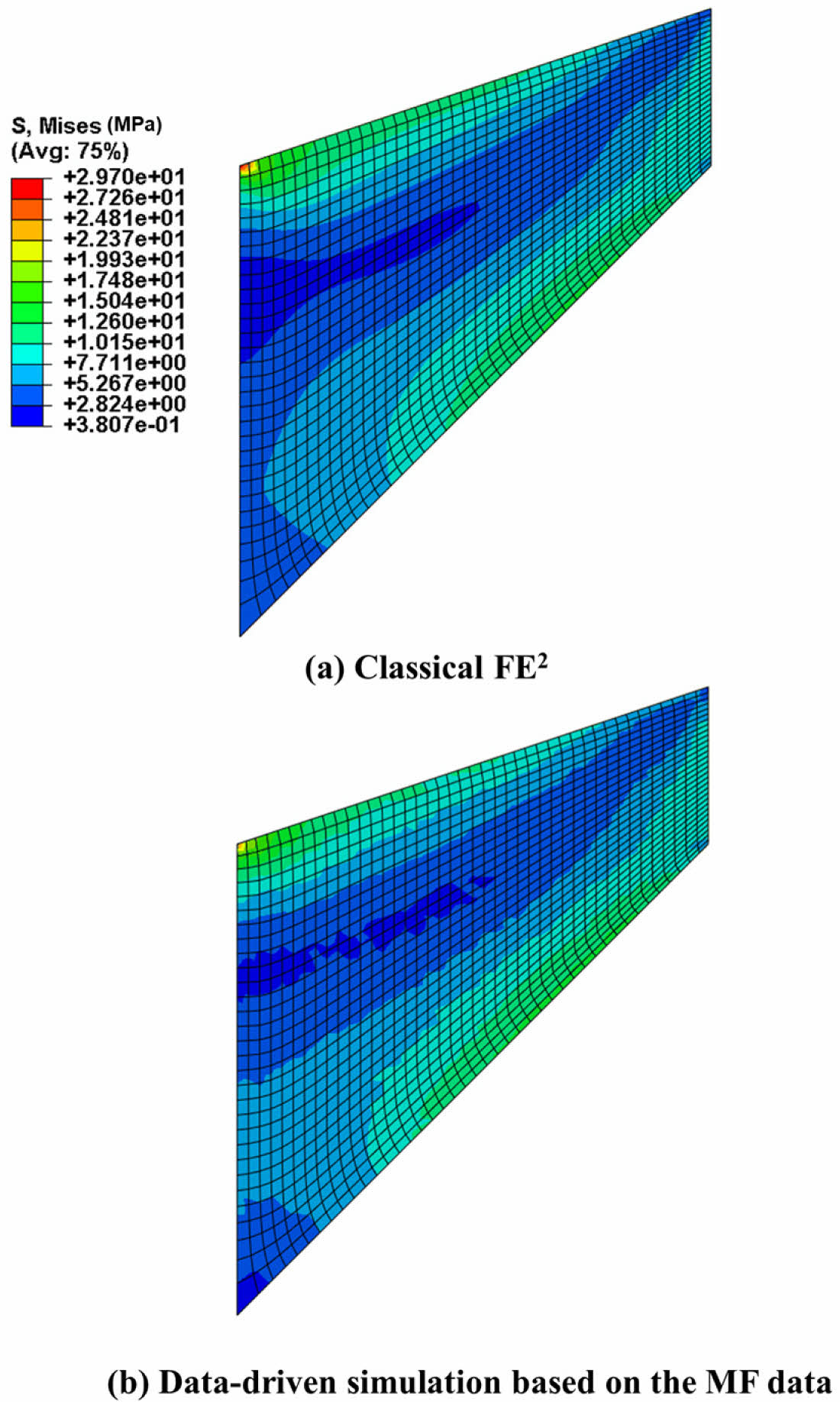
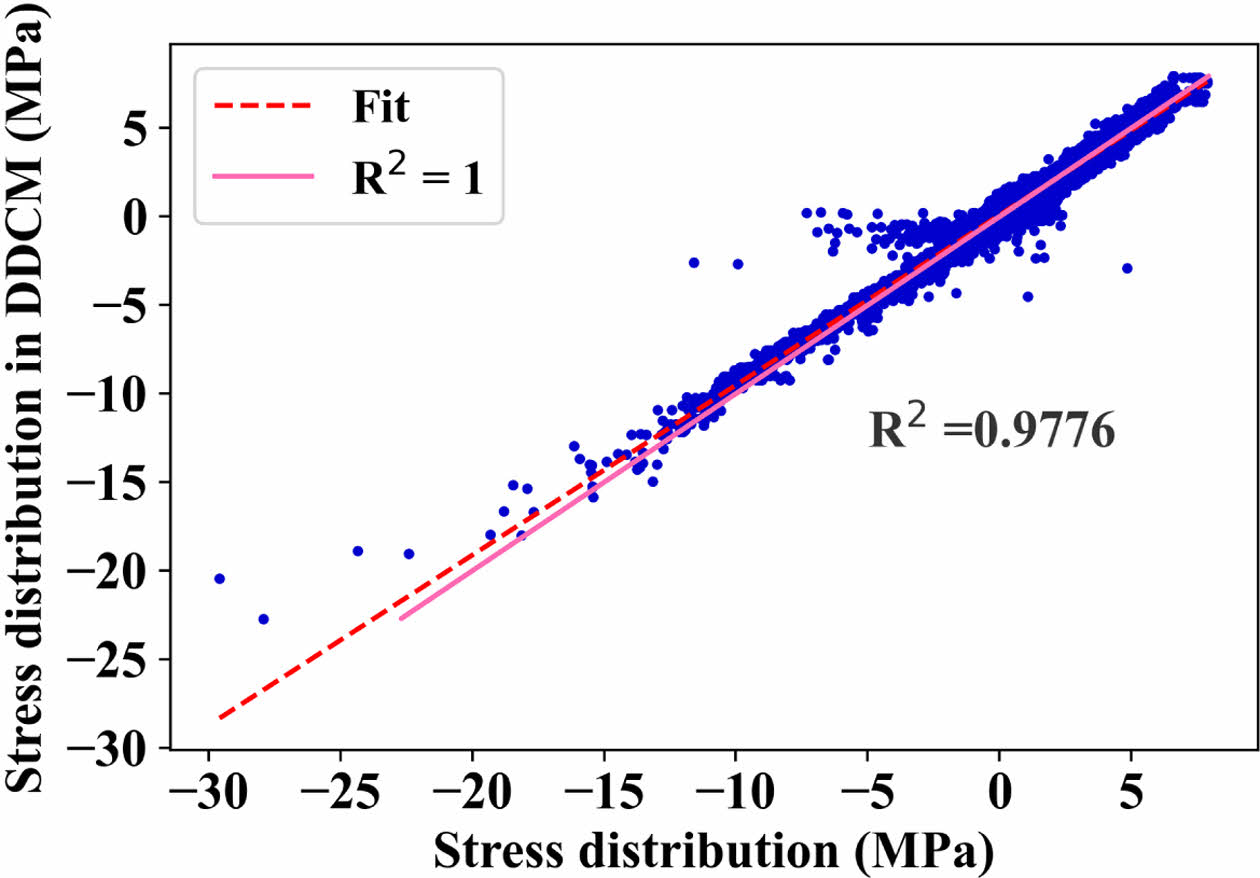
2.2장의 전체적인 데이터 기반 컴퓨팅 과정은 MATLAB in-house 코드로 진행하였고, ABAQUS 서브루틴의 SIGINI함수를 이용한 응력 매핑을 통해서 DDCM 프레임워크를구현시켰다[22]. 그 결과 Fig. 3을 보면, 초탄성 복합재의 미시 스케일을 고려한 거시 구조문제의 von Mises 응력 분포를 확인할 수 있다. 데이터 기반 시뮬레이션 결과와 기존 FE2 해석 결과를 Fig. 4를 통해 정량적으로 비교하였다. Fig. 4의 결정계수(R2)는 정량적으로 데이터 기반 시뮬레이션 결과가 기존 FE2결과와의 적합도를 가리키는 지표로, 값 범위는 0부터 1까지가 되며, 1에 가까울 수록 더 정확하다는 것을 의미한다. 계산 결과 R2는 0.9776로 정확성이 높음을 확인하였다.
총 소요 시간은 i9-10900K CPU @ 3.70GHz 프로세서 기준으로 미시적 오프라인 컴퓨팅에서 데이터베이스 생성은 약 30분, 거시적 온라인 컴퓨팅에서 데이터 기반 컴퓨팅 시뮬레이션은 약 10분 정도 소요되었다. 이때, 평균장 균질화 기법을 이용하여 계산할 경우 약 0.076초가 소요된다. 이는 빠른 계산 속도를 가지며, 미시적 오프라인 컴퓨팅을 효율적으로 수행할 수 있었다. 또한, 미시적 오프라인 컴퓨팅 과정을 통해 데이터베이스를 구축하면, 이후에도 거시 구조의 경계 조건 및 하중 조건이 변화하더라도 사전에 구축한 데이터베이스를 지속적으로 활용할 수 있다. 이러한 제안된 기법을 통해, 멀티스케일 문제를 효율적으로 해결할 수 있었다.
|
Fig. 1 Mean field homogenization-based data-driven computing framework |
|
Fig. 2 Cook’s membrane FE model |
|
Fig. 3 Distribution of macroscopic von Mises stress: (a) classical FE2 ; (b) data-driven computing simulation based on the MF data |
|
Fig. 4 Comparison of stress distribution between DDCM Based on MF Data and classical FE2 |
본 연구에서는 멀티스케일 해석을 위해 평균장 균질화 데이터 기반 전산 시뮬레이션을 제시하였다. 개발된 멀티스케일 해석 프레임워크는 미시적 오프라인 컴퓨팅과 거시적 온라인 컴퓨팅으로 분리하여 멀티스케일 분석을 수행하였다. 구체적으로, 오프라인 컴퓨팅에서는 비선형 균질화 데이터를 미리 생성하는 작업을 진행하였다. 초탄성 복합재의 2상을 고려한 미시 경계치 문제는 평균장 균질화 이론을 통해 효율적으로 계산하여 데이터베이스를 구축할 수 있었다. 그 다음, 거시적 온라인 컴퓨팅은 미리 생성한 균질화 데이터베이스를 기반으로 한 데이터 기반 컴퓨팅에 의해 구조의 모든 적분점에 적절한 변형률-응력 데이터 셋을 할당하면서 시뮬레이션 결과를 도출할 수 있었다. 따라서, 데이터 기반 멀티스케일 프레임워크를 활용하여 FE2의 효율성을 향상시키고, 이를 통해 복합재료 및 구조 시스템의 해석을 성공적으로 수행하였다.
향후 연구에서는 멀티스케일 해석 문제에 대해 탄소성(elastoplasticity) 및 점탄성(viscoelasticity) 모델과 같은 역사 종속적 (history-dependent) 재료 거동을 포함하는 방식으로 접근법을 확장할 것이다.
본 연구 성과는 2021년도 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 수행된 연구임(No. 2021R1C1C1004353).
- 1. Shin, H., and Cho, M., “Multiscale Model to Predict Fatigue Crack Propagation Behavior of Thermoset Polymeric Nanocomposites,” Composites Part A: Applied Science and Manufacturing, Vol. 99, 2017, pp. 23-31.
-
- 2. Shin, H., Choi, J., and Cho, M., “An Efcient Multiscale Homogenization Modeling Approach to Describe Hyperelastic Behavior of Polymer Nanocomposites,” Composites Science and Technology, Vol. 175, 2019, pp. 128-134.
-
- 3. Wang, H., and Shin, H., “Infuence of Nanoparticulate Diameter on Fracture Toughness Improvement of Polymer Nanocomposites by a Nanoparticle Debonding Mechanism: A Multiscale Study,” Engineering Fracture Mechanics, Vol. 261, 2022, pp. 108261.
-
- 4. Shin, H., “Multiscale Model to Predict Fracture Toughness of CNT/epoxy Nanocomposites,” Composite Structures, Vol. 272, 2021, pp. 114236.
-
- 5. Lee, W., and Shin, H., “Temporal Homogenization Formula for Viscoelastic-viscoplastic Model Subjected to Local Cyclic Loading,” International Journal for Numerical Methods in Engineering, Vol. 124, No. 4, 2023, pp. 808-833.
-
- 6. Kim, J.H., Wang, H., Lee, J., and Shin, H., “Multiscale Bridging Method to Characterize Elasto-plastic Properties of Polymer Nanocomposites,” Mechanics of Advanced Materials and Structures, 2022, pp. 1-15.
-
- 7. Lee, W., Kim, S., Sim, H.J., Lee, J.H., An, B.H., Kim, Y.J., Jeong, S.Y., and Shin, H., “Development of Homogenization Data-based Transfer Learning Framework to Predict Effective Mechanical Properties and Thermal Conductivity of Foam Structures,” Composites Research, Vol. 36, No. 3, 2023, pp. 205-210.
-
- 8. Lee, S., and Ryu, S., “A Review of Mean-Field Homogenization for Effective Physical Properties of Particle-Reinforced,” Composites Research, Vol. 33, No. 2, 2020, pp. 81-89.
-
- 9. Raju, K., Tay, T.E., and Tan, V.B.C., “Review of the FE2 Method for Composites,” Multiscale and Multidisciplinary Modeling, Experiments and Design, Vol. 4, 2021, pp. 1-24.
-
- 10. Yvonnet, J., and He, Q.-C., “The Reduced Model Multiscale Method (R3M) for the Non-linear Homogenization of Hyperelastic Media at Finite Strains,” Journal of Computational Physics, Vol. 223, No. 1, 2007, pp. 341-368.
-
- 11. Yvonnet, J., Zahrouni, H., and Potier-Ferry, M., “A Model Reduction Method for the Post-buckling Analysis of Cellular Microstructures,” Computer Methods in Applied Mechanics Engineering, Vol. 197, No. 1-4, 2007, pp. 265-280.
-
- 12. Kim, S., and Shin, H., “Data-driven Multiscale Finite Element Method Using Deep Neural Network Combined with Proper Orthogonal Decomposition,” Engineering with Computers, 2023, pp. 1-15.
-
- 13. LE, B.A., Yvonnet, J., and He, Q.-C., “Computational Homogenization of Nonlinear Elastic Materials Using Neural Networks,” International Journal for Numerical Methods in Engineering, Vol. 104, No. 12, 2015, pp. 1061-1084.
-
- 14. Lu, X., Giovanis, D.G., Yvonnet, J., Papadopoulos, V., Detrez, F., and Bai, J., “A Data-driven Computational Homogenization Method Based on Neural Networks for the Nonlinear Anisotropic Electrical Response of Graphene/polymer Nanocomposites,” Computational Mechanics, Vol. 64 No. 2, 2019, pp. 307-321.
-
- 15. Xu, R., Yang, J., Yan, W., Huang, Q., Giunta, G., Belouettar, S., Zahrouni, H., Ben, Zineb, T., and Hu, H., “Data-driven Multiscale Finite Element Method: From Concurrence to Separation,” Computer Methods in Applied Mechanics and Engineering, Vol. 363, 2020, pp. 112893.
-
- 16. Kirchdoerfer, T., and Ortiz, M., “Data-driven Computational Mechanics,” Computer Methods in Applied Mechanics Engineering, Vol. 304, 2016, pp. 81-101.
-
- 17. Kirchdoerfer, T., and Ortiz, M., “Data Driven Computing with Noisy Material Data Sets,” Computer Methods in Applied Mechanics Engineering, Vol. 326, 2017, pp. 622-641.
-
- 18. Kirchdoerfer, T., and Ortiz, M., “Data-driven Computing In Dynamics,” International Journal for Numerical Methods in Engineering, Vol. 113, No. 11, 2018, pp. 1697-1710.
-
- 19. Eggersmann, R., Kirchdoerfer, T., Reese, S., Stainier, L., and Ortiz, M., “Model-free Data-driven Inelasticity,” Computer Methods in Applied Mechanics Engineering, Vol. 350, 2019, pp. 81-99.
-
- 20. Eggersmann, R., Stainier, L., Ortiz, M., and Reese, S., “Efficient Data Structures for Model-free Data-driven Computational Mechanics,” Computer Methods in Applied Mechanics Engineering, Vol. 382, 2021, pp. 113855.
-
- 21. Karapiperis, K., Stainier, L., Ortiz, M., and Andrade, J. E., “Data-driven Multiscale Modeling in Mechanics,” Journal of the Mechanics and Physics of Solids, Vol. 147, 2021, pp. 104239.
-
- 22. Kim, S., and Shin, H., “Deep Learning Framework for Multiscale Finite Element Analysis Based on Data-driven Mechanics and Data Augmentation,” Computer Methods in Applied Mechanics Engineering, Vol. 414, 2023, pp. 116131.
-
- 23. Pierard, O., and Doghri, I., “An Enhanced Affine Formulation and the Corresponding Numerical Algorithms for the Mean-field Homogenization of Elasto-viscoplastic Composites,” International Journal of Plasticity, Vol. 22, No. 1, 2006, pp. 131-157.
-
- 24. Pierard, O., Friebel, C., and Doghri, I., “Mean-field Homogenization of Multi-phase Thermo-elastic Composites: A General Framework and Its Validation,” Composites Science and Technology, Vol. 64, No. 10-11, 2004, pp. 1587-1603.
-
- 25. Doghri, I., El Ghezal, M.I., and Adam, L., “Finite Strain Mean-field Homogenization of Composite Materials with Hyperelastic-plastic Constituents,” International Journal of Plasticity, Vol. 81, 2016, pp. 40-62.
-
- 26. Nguyen, L.T.K., Rambausek, M., and Keip, M.A., “Variational Framework for Distance-minimizing Method in Data-driven Computational Mechanics,” Computer Methods in Applied Mechanics and Engineering, Vol. 365, 2020, pp. 112898.
-
- 27. Nguyen, L.T.K., Aydin, R.C., and Cyron. C.J., “Accelerating the Distance-minimizing Method for Data-driven Elasticity with Adaptive Hyperparameters,” Computational Mechanics, Vol. 70, No. 3, 2022, pp. 621-638.
-
 This Article
This Article
-
2023; 36(5): 329-334
Published on Oct 31, 2023
- 10.7234/composres.2023.36.5.329
- Received on Jul 5, 2023
- Revised on Aug 21, 2023
- Accepted on Sep 27, 2023
Services
Shared
Correspondence to
- Hyunseong Shin
-
Department of Mechanical Engineering, Inha University, Incheon 22212, Korea
- E-mail: shs1106@inha.ac.kr
Gangnam Mirae Tower, Suite 601, 174 Saimdang-ro, Seocho-gu, Seoul 06627, South Korea
Tel: +82-2-598-1550 Fax: +82-2-598-1557 E-mail: composites@kscm.re.kr