





- A Study on the Design of Glass Fiber Fabric Reinforced Plastic Circuit Analog Radar Absorber Structure Using Machine Learning and Deep Learning Techniques
Jae Cheol Oh*, Seok Young Park*, Jin Bong Kim*† , Hong Kyu Jang*, Ji Hoon Kim*, Woo-Kyoung Lee*
* Composites Research Division, Korea Institute of Materials Science (KIMS), Korea
- 머신러닝 및 딥러닝 기법을 활용한 유리섬유 직물 강화 복합재 적층판형 Circuit Analog 전파 흡수구조 설계에 대한 연구
오재철* · 박석영* · 김진봉*† · 장홍규* · 김지훈* · 이우경*
This article is an open access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
In this paper, a machine learning and deep learning model for the design of circuit analog (CA) radar absorbing structure with a cross-dipole pattern on a glass fiber fabric reinforced plastic is presented. The proposed model can directly calculate reflection loss in the Ku-band (12-18 GHz) without three-dimensional electromagnetic numerical analysis based on the geometry of the Cross-Dipole pattern. For this purpose, the optimal learning model was derived by applying various machine learning and deep learning techniques, and the results calculated by the learning model were compared with the electromagnetic wave absorption characteristics obtained by 3D electromagnetic wave numerical analysis to evaluate the comparative advantages of each model. Most of the implemented models showed similar calculated results to the numerical results, but it was found that the Fully-Connected model could provide the most similar calculated results
본 논문에서는 유리섬유 직물 강화 복합재 소재위에 Cross-Dipole 패턴이 배치된 정형적 Circuit Analog(CA) 전파 흡수 구조 설계를 위한 머신러닝 및 딥러닝 모델을 제시하였다. 제시된 모델은 Cross-Dipole 패턴의 형상에 따라서 Ku-band (12-18 GHz)에서의 전파흡수성능을 3차원 전자파 수치해석 없이 바로 계산할 수 있다. 이를 위하여 다양한 머신러닝 및 딥러닝 기술을 적용한 최적 학습 모델을 도출하고, 학습 모델이 계산한 결과를 3차원 전자파 수치해석결과로 얻은 전파흡수특성과 비교함으로써 각각의 모델 간의 성능의 비교우위를 평가하였다. 개발된 모델들은 대부분 수치해석결과와 유사한 계산결과를 보여주었지만, 그 중 Fully-Connected 모델이 가장 유사한 계산결과를 제공할 수 있음을 확인하였다
Keywords: 복합재료(Composite Materials), 머신러닝(Machine Learning), 딥러닝(Deep Learning), 전자파 흡수 구조(Radar Absorbing Structure), 유리섬유 직물 강화 복합재(Glass Fiber Reinforced Plastic)
무선 통신 기술의 발전에 따라 민간, 방위 산업 분야에서 전파 흡수 기술에 대한 관심이 높아지고 있다[1]. 특히 현대전(Modern Warfare)에서 전자파 기술을 활용한 전자전(Electronic Warfare)의 중요도가 크게 증가하고 있다. 전자전의 방어적 측면에서는 적의 레이다(Radar)에 탐지 당하지 않도록 형상이 낮은 Radar Cross Section(RCS) 값을 가지게 하는 저피탐 설계 기술이 중요하다. 이러한 저피탐 설계 기술은 운용 속도가 매우 빠르고 작전 고도가 높아 육안으로 탐지가 어려워 전자기파를 이용한 레이다에 전적으로 의존해야 하는 항공 분야에서 매우 중요한데[2], 무인 드론 기술이 도래하고 그 작전 수행 빈도가 증가함에 따라 저피탐 설계 기술의 중요도는 더욱 높아지고 있다. 전파 흡수 구조 설계의 핵심이론은 전송선 이론(Transmission Line Theory)으로[3], 레이다 주파수 대역에서 전파 흡수 구조의 입력 임피던스 값을 공기의 특성 임피던스인 377 ohm에 매칭하여 공기와 전파 흡수 구조 계면에서 반사되는 전파를 최소화하는 것이 전파 흡수 구조 설계의 목표이다. Circuit Analog(CA) 전파 흡수 구조는 면저항 값을 가지고 있는 주기성 패턴을 Substrate에 적용한 형태로 그 원리상 377 ohm 공진 주파수가 1개뿐인 Salisbury Screen 방식[4,5]과 비교할 때 입력 임피던스 377 ohm 공진점을 2개 이상 확보 가능하여 광대역 설계가 가능한 장점이 있다[6,7]. 또, Substrate로 기계적 성능 및 내환경성이 검증된 소재를 사용하면 Substrate 소재의 기계적 성능과 내환경성을 그대로 활용 가능하여 가혹한 운용환경에 놓이는 무기 체계 적용에 유리한 장점[8-11]이 있다. 항공 무기 체계용 CA 전파 흡수 구조 Substrate는 비강도가 좋고 내부식성 등이 좋은 유리 섬유 복합재를 주로 사용한다[12]. 이러한 전파 흡수 구조의 주기성 패턴은 전파 흡수 주파수 대역에 따라 재설계 및 최적화를 필요로 하므로 상당한 량의 설계 자원을 수반하는 문제점이 있는데, 별도의 전자기 해석없이 CA 전파 흡수 구조 전자기 성능 예측이 가능한 모델을 구현하고 이를 이용해서 목표 전파 흡수 성능을 만족하는 패턴 형상을 설계할 수 있다면 설계에 필요한 자원을 크게 감소시켜 설계 효율성 제고가 가능할 것으로 판단된다.머신러닝 및 딥러닝 기술은 문제 해결에 적합한 학습 모델 선정 및 학습 Data량이 뒷받침된다면 손쉽게 정확도가 높은 예측 모델 구현이 가능하여 전파 흡수 구조 설계 설계를 위한 연구도 진행되고 있다. Wu[13]는 딥러닝 기술을 Indium tin oxide 소재 전파 흡수 구조의 설계에 적용하였는데, Genetic Algorithm의 Correction Parameter 값을 계산하는 용도로 사용하였다. On[14]은 딥러닝 기술을 Pixel 타입의 주기성 패턴의 설계에 적용하였으나 CA 전파 흡수 구조의 광대역 전파흡수 성능의 주요한 요건인 두 개의 흡수 피크를 확보하지는 못하는 설계결과를 제시하였다.
이에 본 논문에서는 Liu[15]의 연구를 통해 전자기 특성이 검증된 Cross-Dipole CA 전파 흡수 구조 설계를 위한 머신러닝 및 딥러닝 모델을 구현하고 그 성능을 비교하여 효율적인 CA 전파 흡수 구조 설계를 위해 적합한 모델을 제시하고 이를 이용해 CA 전파 흡수 구조 설계 효율성을 제고하고자 한다.
2.1 전자기 해석 모델 및 Data 생성
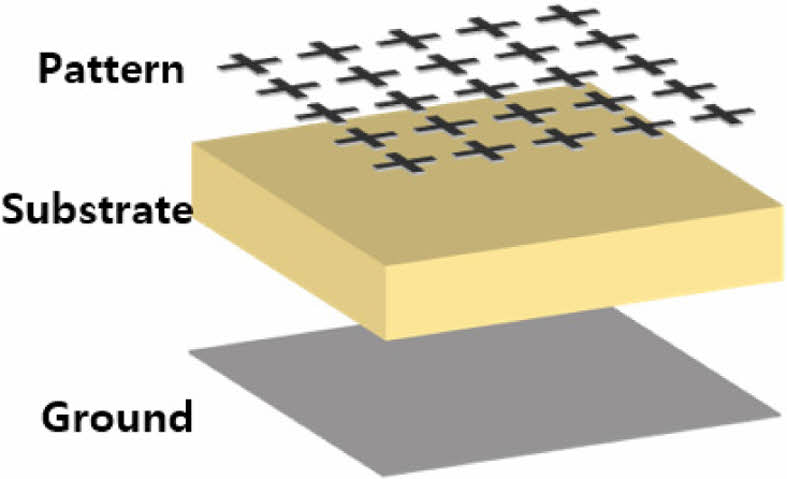
머신러닝 및 딥러닝에 사용하기 위한 Data 생성을 위해 상용 전자기 해석 프로그램을 이용하였다. 설계 변수별로 실제 시편을 제작하고 전파 흡수 성능 측정 결과를 이용하는 방법이 가장 유효하나, 학습에 충분한 Data 생성을 위해 필요한 량의 시편을 제작하기 위해서는 상당한 비용과 시간이 소요되므로 본 논문에서는 해석-실제 측정 결과 비교를 통해 CA 전파 흡수 구조 설계시 그 정확도가 검증된 Dassualt Systems의 CST를 사용하였다[7,10]. CST 해석 프로그램을 사용하여 CA 전파 흡수 구조 전자기 해석 모델을 구현하고 이를 이용해 머신러닝 및 딥러닝 학습 및 검증용 File을 생성하였다. 전파 흡수 구조의 주파수 대역은 무인기 형상 적용을 목표로, 무인기 탐지 시스템의 주파수 대역에서 저피탐 성능 확보가 가능하도록 Ku-band로 결정하였다[16]. Fig. 1과 Table 1은 각각 CA 전파 흡수 구조의 구성과 구성 소재 별 물성, 두께를 보여준다.
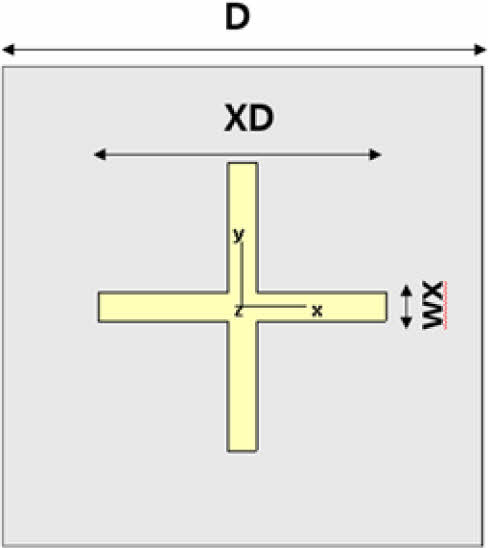
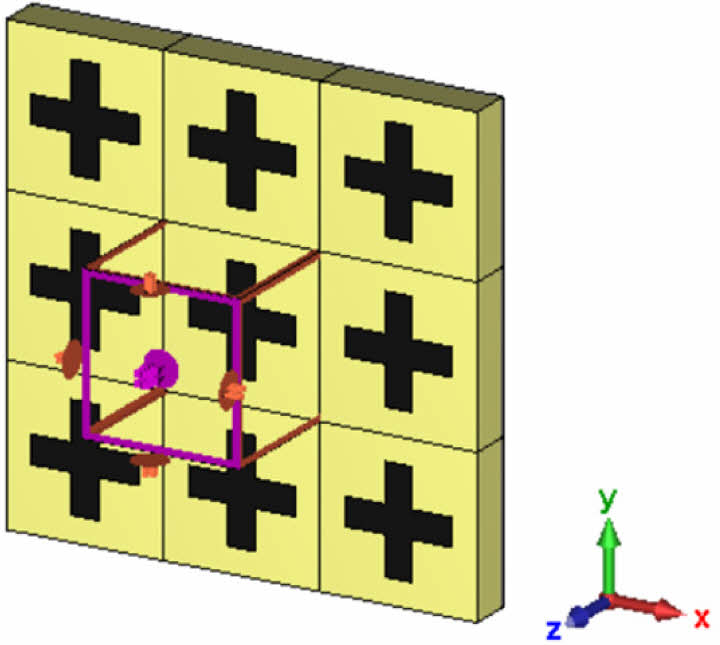
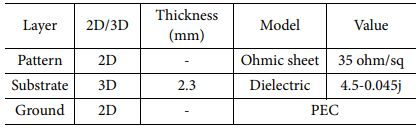
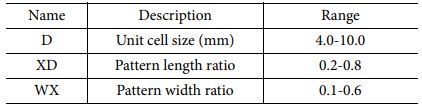
CA 전파 흡수 구조는 저항성(전도성) 패턴, Substrate, Ground 층으로 구성이 된다. 패턴과 Ground층은 2D Sheet 모델을 사용하였고 Substrate 층은 3D Solid 모델을 사용하였다. 패턴의 면저항 값은 스크린 프린팅 장비와 상용 카본 잉크 소재로 구현 가능한 면저항 값을 고려하여 35 ohm/sq를 2D Ohmic Sheet 모델에 사용하였다[7]. Substrate의 유전율은 항공용으로 사용이 검증된 유리섬유 직물 강화 복합재 소재인 MXB 7668/7781 Glass Epoxy Prepreg 소재의 자유공간 측정장비 유전율 측정값을 사용했다. 측정 값은 유전율 실수부 4.5, 허수부 0.045이다. Substrate의 두께는 CA 전파 흡수 구조 두께로 일반적으로 널리 사용하는 1/4 파장 값을 사용했다[7]. 파장 계산에 사용한 주파수 기준 값은 15 GHz로, 계산 결과 약 2.3 mm였다. Ground 반사판 소재 해석 모델에는 Perfect Electric Conductor(PEC)를 사용하였다. 패턴의 형상은 Cross-Dipole 패턴을 이용하였는데[15], Cross-Dipole 패턴의 해석 변수들은 Fig. 2와 Table 2에 명시된 바와 같이 D, XD, WX 3종류를 사용하였다. 변수 D는 패턴간 간격을 포함한 패턴 반복 주기의 절대적인 크기(mm)를, XD는 D 대비 패턴의 상대적 길이 비율을, WX는 패턴의 길이 대비 상대적 선폭 비율을 의미한다. 각 변수 값의 범위는 D는 4부터 10, XD는 0.2부터 0.8, WX 값은 0.1부터 0.6을 사용하였다. CA 전파 흡수 구조는 패턴의 설계에 따라 등가 Capacitance 값과 Inductance 값이 달라지고 이 등가 Capacitance와 Inductance 성분의 공진에 의해 공진 주파수 및 전파 흡수 성능이 결정된다. Cross-dipole 패턴은 타 패턴들과 비교하였을 때 상대적으로 높은 Inductance 값을 가져야 목표 주파수 대역에서 공진점을 확보할 수 있는데[17], Inductance 값은 선폭의 두께에 반비례한다. 따라서 선폭이 너무 크면 등가 Inductance 값이 작아져 목표 주파수 대역에서 공진점을 확보할 수 없다. WX 값이 0.6인 경우 Cross-dipole 패턴의 길이를 한 변의 길이로 하는 정사각형 면적에서 Cross-dipole 패턴의 면적이 84%에 이를 만큼 패턴이 두꺼워지고 비대해져서 적절한 등가 Inductance 값을 확보할 수 없다. 따라서 WX 값은 Cross-dipole 패턴이 적절한 등가 Inductance 값을 가지도록 0.1에서 0.6 사이의 값을 사용하였다.
CST의 solver는 Frequency Domain Solver(F-solver)를 이용하였다. Fig. 3은 해석 모델의 경계조건을 보여준다. Unit-cell Boundary를 X, Y축 방향으로 적용하였다. Unit-cell Boundary는 하나의 Cell이 주기적으로 반복되는 경우에 사용하는 경계 조건으로, 해당 조건 사용시 하나의 Cell이 무한하게 반복된다고 가정, Floquet mode로 해석을 수행한다. 본 논문에서는 X축, Y축 방향으로 패턴이 무한하게 반복된다고 가정하여 X축, Y축 방향으로 해당 경계 조건을 적용하였다. 입사 각도는 X-Y 평면에 수직으로 입사하는 경우만을 고려하였다.
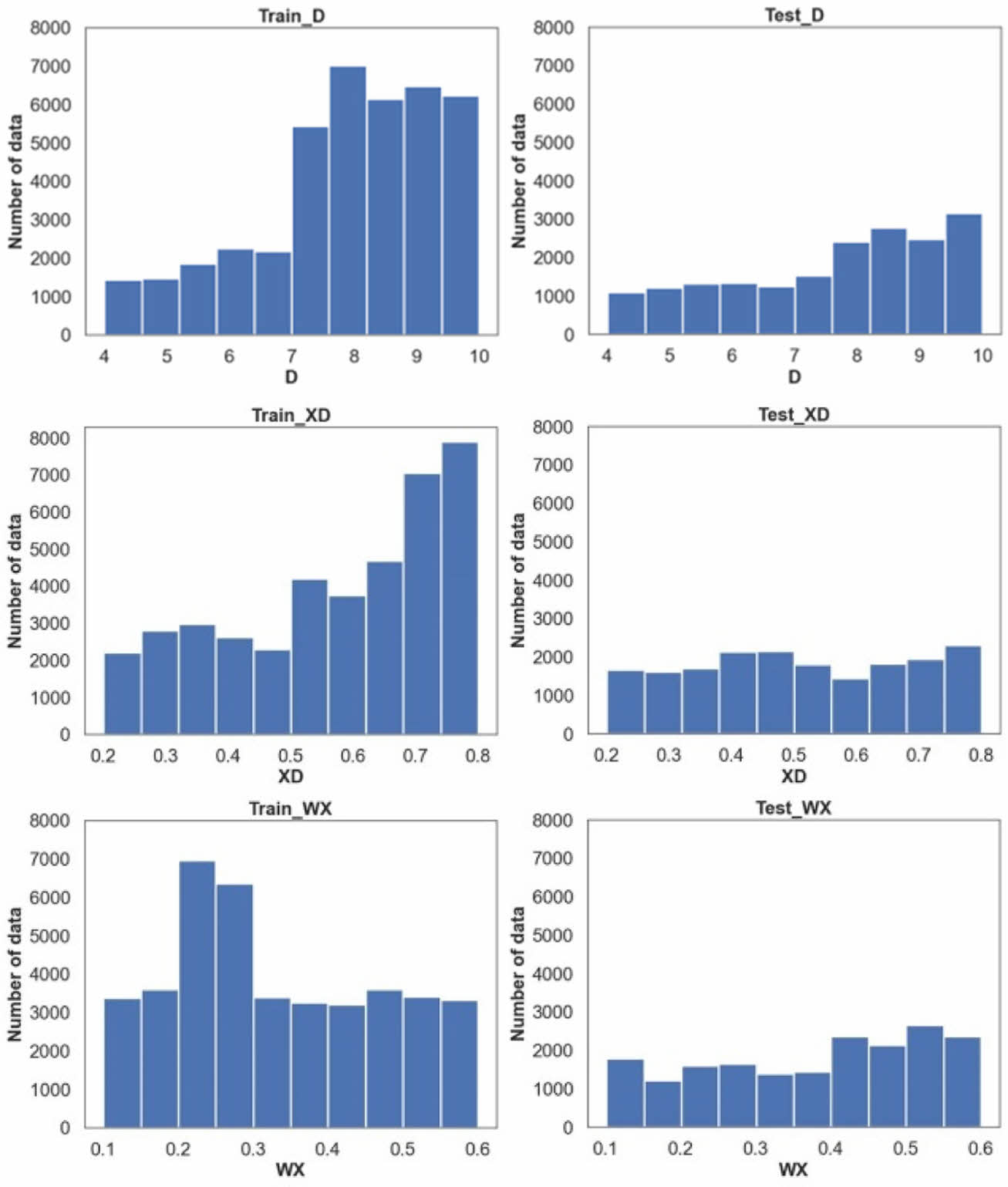
해석 주파수는 0.2 GHz 간격 최소 11 GHz 부터 최대 19 GHz까지로, 하나의 생성 File당 최대 41개의 Points를 가진다. 학습 Data량은 각 설계 변수(D, XD, WX)에 주파수 Points(최대 41개)를 곱해 더한 값이 된다. 머신러닝 및 딥러닝에는 일반적으로 학습을 위한 Data와 검증을 위한 Data 2종류가 필요하다. 학습용으로 1459개의 File을 생성, 40481개의 Data를 생성하였고 검증용으로는 691개의 File을 생성하여 18517개의 Data를 생성하였다. 검증용 Data는 모델 학습에는 영향을 주지 않으며 정확도 검증을 위해 사용된다. Fig. 4는 설계 변수 (D, XD, WX)별 분포를 보여준다. 그 분포가 특정 값에 극단적으로 치우치지 않은 전반적으로 고른 Data 분포를 보여준다.
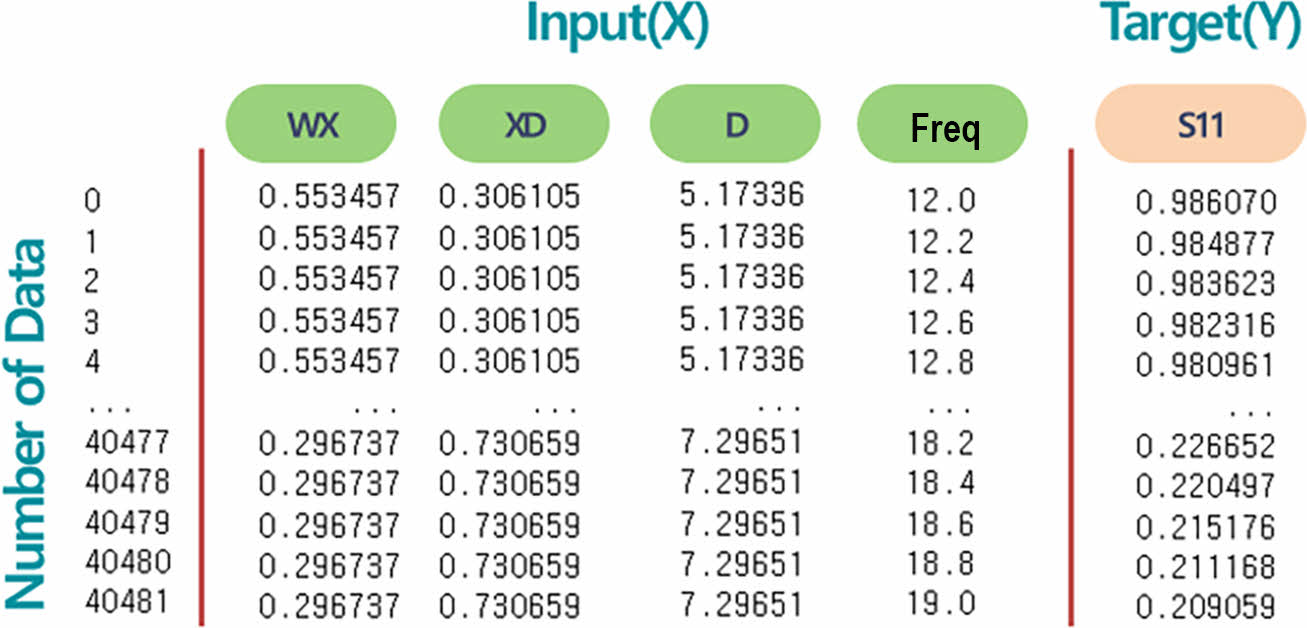
생성된 Data를 이용한 머신러닝 및 딥러닝 모델은 Python언어로 구현이 된다. 따라서 생성된 Data를 Python상으로 Import해 줄 필요가 있다. Data Import에는 Data 입출력 전문 Python Library인 Pandas를 사용하였다. Pandas를 이용하면 대량의 Data를 Data Frame 포맷으로 쉽게 읽어 들일 수 있다. Fig. 5는 학습용으로 생성된 Data가 Data Frame형태로 Import된 결과를 보여준다. 검증용 Data의 경우 그 Data의 수는 다르지만 형식은 학습용과 동일하다. Data의 수량(학습용의 경우 40481)은 모든 File의 주파수 Points 개수 전체 합과 동일하다.
머신러닝 및 딥러닝은 그 목적에 따라 분류 모델과 수치 Data를 Fitting하는 회귀(Regression) 모델로 분류할 수 있는데, CA 전파 흡수 구조 설계에 사용하는 목적 함수 출력값은 전파 흡수 성능(S11)으로, 연속적인 수치 Data이므로 회귀 모델을 이용한다. 회귀 모델에 사용하는 변수는 학습용 입력 변수(X)와 최적화 목표인 Target(Y) 변수로 분류가 되는데 전파 흡수 구조 설계의 최종 목표는 S11(반사계수) 최소화이므로 입력 변수(X)로 해석 변수(D, XD, WX) 값과 주파수(Freq)를, Target(Y) 변수로는 S11 값을 지정해주었다. S11 값은 Linear Scale 값을 학습시에 사용해 주었다.
일반적으로 머신러닝 및 딥러닝을 수행함에 있어 변수 별 Data 범위가 크게 차이가 나면 학습률이 낮아질 수 있는 문제가 있다. 본 Data에서도 D 값의 범위 4-10과 WX 값의 범위 0.1-0.6은 그 차이가 상당하다. 이런 문제를 해결하기 일반적으로 Min-Max 정규화(Normalization)를 널리 사용한다. 그 식은 (1)과 같다.

Min-Max 정규화는 Data의 최소값(xmin)과 최대값(xmax)을 이용하여 Data의 범위를 0과 1 사이로 Scaling 한다. 이후 장에서는 이렇게 입력 및 정규화 된 Data를 이용해서 머신러닝 및 딥러닝을 수행하였다.
2.2 머신러닝
2.1장에서 생성 및 정규화된 Data를 기반으로 머신러닝을 수행하였다. 머신러닝은 그 학습 모델이 매우 다양한데, 본 논문에서는 회귀용 머신러닝 학습모델 중에서 널리 사용하는 Support Vector Regressor(SVR), Decision Tree, Random Forest, 그리고 K-Nearest Neighbor(KNN) 모델을 이용하였다. Polynomial 모델이나 Genetic Algorithm을 이용하는 Symbolic Regression 모델도 널리 사용되나 해당 모델들은 머신러닝이 아닌 일반적인 수치 최적화에도 많이 사용하는 모델이므로 그 사용을 배제하였다. SVR은 분류에 널리 사용하는 Support Vector Machine(SVM)의 원리를 회귀 모델에 적용한 모델로, 분류시 오차를 최소화하도록 서로 다른 두 Group 사이 최대 Margin을 가지는 경계선을 생성하는 방식으로 학습을 수행한다. Decision Tree 및 Random Forest는 의사 결정 나무(Decision Tree)를 생성하여 분류 또는 회귀에 사용하는 모델로 Random Forest는 복수의 Decision Tree를 생성, 그 결과를 조합하여 최종 결론을 도출하므로 Decision Tree 모델보다 일반적으로 높은 정확도를 보여준다. KNN 모델도 SVM처럼 분류에 널리 사용하는 모델로, 새로운 Data가 입력되었을 때 가장 근처에 있는 Data와 동일 Group으로 분류하는 원리로 학습을 수행한다. 각 학습 모델은 Python의 Scikit Learn Library에서 제공하는 모델을 사용하였다. 머신러닝 모델은 입력 변수(X), Target(Y)변수 외에 Tuning을 위한 Hyper Parameter 값을 가진다. Hyper Parameter 값에 따라 학습 성능이 달라지는데 일반적으로 머신러닝은 Hyper Parameter에 의한 성능 변화가 딥러닝 보다는 적고 본 논문의 목표는 머신러닝 모델 중 어떤 모델이 정형적 CA 전파 흡수 구조 설계에 최적인지 확인하는 것이므로 머신러닝에 사용한 4가지 모델의 Hyper Parameter 값은 별도의 Tuning 과정을 거치지 않고 각 학습 모델에서 기본으로 제공하는 값을 사용하였다.
학습된 모델의 정확도는 학습에 사용하지 않은 별도의 검증용 data 설계 변수(D, XD, WX) 값과 주파수(Freq)를 학습된 모델에 입력해 주었을 때 모델의 전파 흡수 성능(S11) 예측값과 검증용 data의 CST 해석 S11 값 사이의 오차를 수치화하여 계산한다. 본 논문에서는 오차 수치화 방법들 중에서 모델 정확도 검증을 위해 머신러닝 및 딥러닝 모델 평가에 일반적으로 널리 사용하는 R-square 값과 Mean Absolute Percentage Error(MAPE)를 사용하였다. 그 수식은 각각 (2), (3)과 같다.
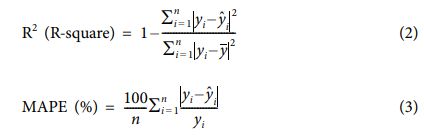
yi는 실제 Data 값(CST 해석 S11)을, Ῡ는 Data의 평균값을, Ῠi는 학습 모델을 이용해서 예측한 값(학습 모델을 이용해서 예측한 S11)을 의미한다. R-square 값은 편차 제곱의 합과 학습모델 예측값-실제값 사이의 오차 제곱의 합의 비를 1에서 뺀 값이다. 분모인 편차 제곱합은 Data가 고정된 상태에서는 일정하므로 학습 모델 예측값과 실제값 사이의 오차가 적을수록 R-square 값은 1에 가까운 값을 가지며 이는 모델 정확도가 높음을 의미한다. MAPE 값은 예측값Ῠi과 실제값 yi의 오차 백분률의 총합으로 그 값이 낮을수록 정확도가 높다.
2.3 딥 러닝
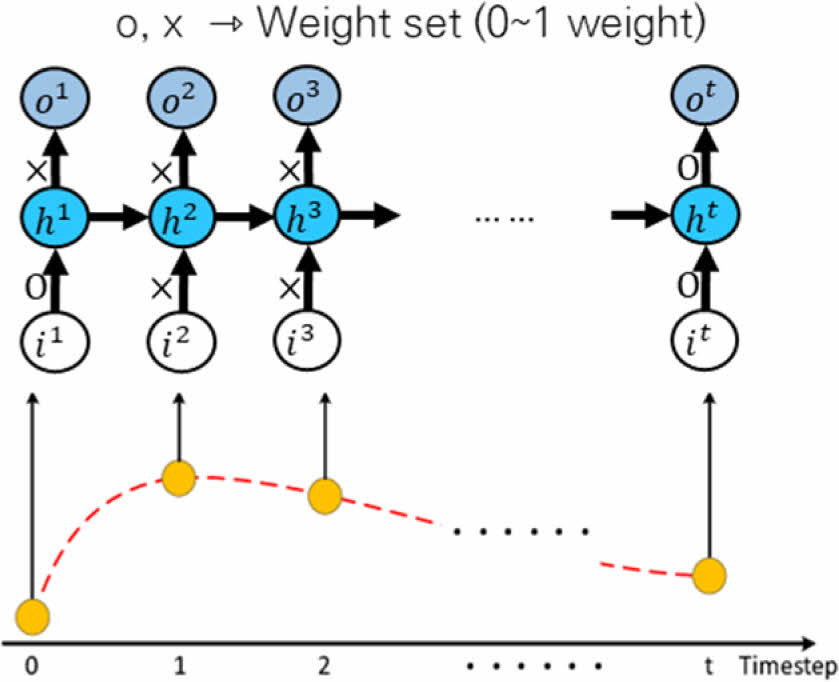
머신러닝과 동일하게 2.1장에서 생성 및 정규화된 Data를 기반으로 딥러닝을 수행하였다. 딥러닝은 인간의 뉴런 모델을 모사한 방식으로 학습을 수행하는데, 일반적으로 그 연산량이 머신러닝에 비해 매우 많으며 가중치(Weight)를 Update하며 학습을 수행하는 특징이 있다. 딥러닝은 입력/출력 층과 마주하는 Layer 외 그 사이 학습을 위한 숨겨진 Hidden Layer층이 존재하며, 이러한 Hidden Layer층의 존재 때문에 딥(Deep) 러닝으로 불린다. 딥러닝은 학습의 정확도가 높아 이미지 처리 및 합성, 음석 인식등 다양한 분야에서 활용되고 있다. 여러가지 딥러닝 모델중에서 본 논문에서는 문제 해결에 적합할 것으로 판단된 두 종류의 모델을 사용하였는데, Long Short-Term Memory(LSTM) 모델과 Fully-Connected 모델이 그 것이다. LSTM은 Recurrent Neural Network(RNN)을 개선한 모델로, Sequential 한 Data의 흐름에 따라 Weight 값을 Update 하며 필요시 Forget Gate를 이용하여 이전의 Data가 학습에 미치는 영향성을 조절할 수 있다.
Fig. 6은 LSTM 모델의 Weight Update 모식도를 보여준다.
LSTM 모델은 Sequential 한 Data의 입력에 따라 Weight를 Update하는데, Sequential한 data의 경우 인접한 값끼리는 멀리 떨어진 경우 보다 Data의 값이 비슷할 확률이 높으므로 Parameter Sharing이 가능한 장점이 있다[18]. 따라서 주가 예측 같은 시계열 Data나 주변 문맥 이 중요한 언어 처리 학습에 널리 사용되고 있다. CA 전파 흡수 구조의 Target(Y)변수인 S11 값 역시 인접한 주파수에서는 유사한 S11 값을 가진다는 점에 착안하여 LSTM 모델을 적용해 보았다.
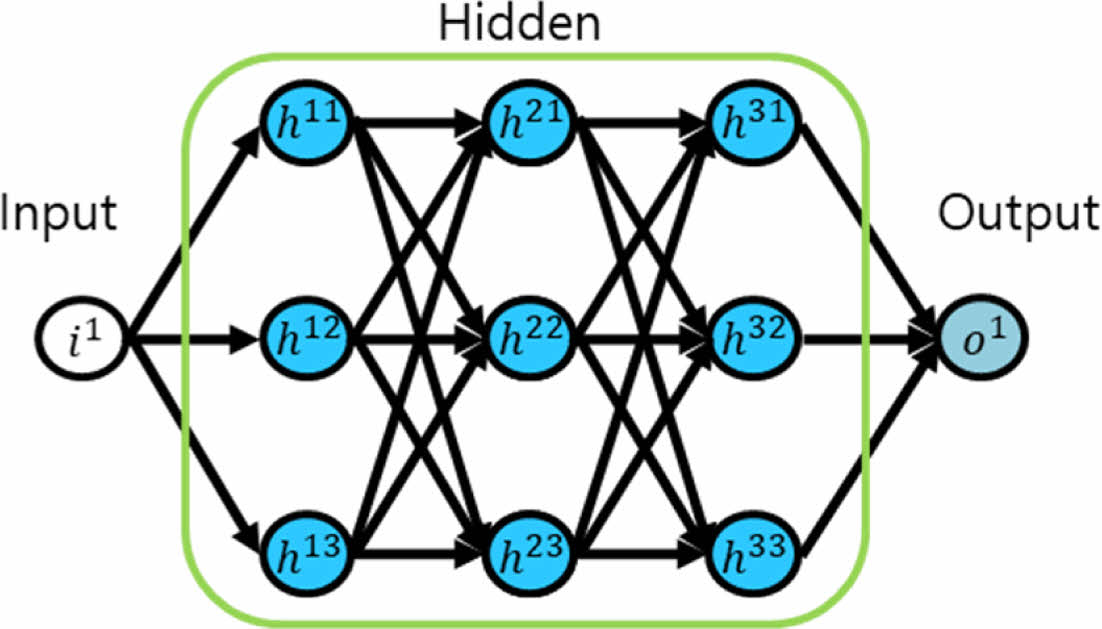
Fig. 7은 Fully-Connected(FC) 모델 Weight Update 모식도를 보여준다. Fully-Connected 모델은 그 이름이 의미하듯 입력, 출력 및 Hidden Layer의 Node가 동일 계층을 제외하고는 전부 연결되어 있다. 이 때문에 Node수와 층수(Depth)가 증가할수록 그 연산량이 폭발적으로 증가한다. Fully-Connected 모델과 LSTM 모델의 주요한 차이점은 LSTM 모델과 달리 Fully-Connected 모델은 Parameter Sharing이 없다는 점이다.
딥러닝은 머신러닝보다 예측 정확도가 높지만, 그 성능이 Optimizer, Loss Function 및 Hyper Parameter Tuning에 따라 크게 영향을 받는다. 따라서 모델에 적합한 Optimizer 설정 및 Hyper Parameter 값 설정이 매우 중요하다. LSTM 모델에서 사용한 Optimizer, Function 및 Hyper Parameter 정보는 Table 3, 4와 같다.
Adam Optimizer는 Hyper Parameter 변화에 Robust하여 널리 사용되는 Optimizer로, 모델 검증에 적합할 것으로 판단되어 사용하였다. Loss Function은 회귀문제에서 널리 사용하는 Mean Absolute Error(MAE)를 이용하였으며, 이는 식(4)에 나타난 바와 같다.
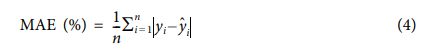
MAE는 실제값 yi와 예측값 Ῠi 사이의 오차의 합의 평균을 의미한다. Activation Function은 Vanishing Gradient 문제에서 상대적으로 우수한 성능을 보여주는 Rectified Linear Unit(ReLU)를 사용하였다[18].
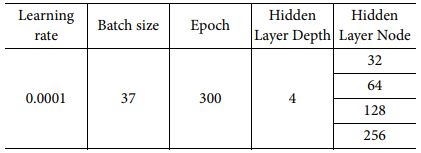
Hyper parameter는 Learning rate, Batch size, Epoch, Hidden Layer Depth, Hidden Layer Node 총 5종류를 사용하였다. Learning rate는 LSTM에서 일반적으로 많이 사용하는 값 중 하나인 0.0001을 사용하였다. Batch size는 한번에 처리할 수 있는 Data의 량으로 Batch size가 크면 빠르게 학습을 수행할 수 있으나 하드웨어 성능에 따라 그 최대 Batch 값이 제한된다. LSTM 모델에서는 하드웨어의 성능을 고려하여 37을 사용하였다. Epoch는 학습을 수행하는 횟수로, 학습이 충분히 이루어지도록 300으로 설정을 하였다. Hyper Parameter 중 성능에 주요하게 영향을 미치는 것은 Hidden Layer Depth와 Node수이다. Depth가 깊고 Node수가 클수록 좋은 성능을 보여줄 가능성이 크나 필요 이상으로 연산시간이 소요되는 문제가 발생할 수 있다. 단일 Depth를 이용하는 경우 보다 복수의 층을 사용하는 경우 Generalization Error 문제 해결에 유리하지만, 너무 많은 층을 이용하며 Vanishing Gradient 문제가 발생하므로 일반적으로 2-5 사이의 Depth를 사용한다[18]. 본 논문에서는 Depth 값으로 4를 사용하였다. Node 수는 성능과 밀접하게 관련이 있으므로 32부터 256까지 2배씩 증가시키며 각 Node별 학습 성능 및 소요 시간을 비교하였다. 학습 정확도에 사용한 지표는 2.2장과 동일하게 R-square 값과 MAPE 값을 사용하였다.
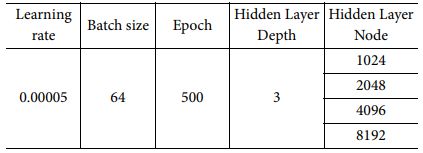
Fully-Connected 모델도 LSTM 모델과 동일한 Optimizer, Loss Function 및 Activation Function을 사용하였다. Learning rate는 널리 사용하는 값 중 하나인 0.00005를, Batch size는 해당 모델에서 하드웨어 성능을 고려하여 64로 설정해 주었으며 충분한 학습을 위해 Epoch 값은 500을 사용하였다. Hidden Layer Depth는 2-5 사이 값 중 하나인 3을 사용하였으며 Node 수를 1024 부터 2배씩 증가시키며 성능 및 학습 시간을 비교하였다. Fully-Connected 모델에서 사용한 Optimizer, Function 및 Hyper Parameter 정보는 Table 5, 6 과 같다.
2.4 결과 및 분석
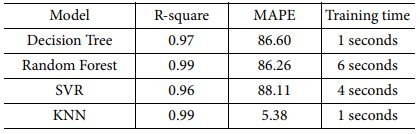
2.1장에서 생성된 Data를 기반으로 2.2장과 2.3장에서 설명한 바와 같이 4종류의 머신러닝 모델과 2종류의 딥러닝 모델의 학습을 수행하였다. 학습에 사용한 하드웨어는 i7 CPU 및 RTX 3070 GPU였다. Table 7은 머신러닝 모델별 정확도 및 학습 시간을 보여준다.
머신러닝의 경우 학습 시간이 모두 수 초급으로 매우 빠르다. KNN 모델이 머신러닝 모델중 R-square 값, MAPE 값, 학습시간 모든 면에서 가장 우수한 것을 확인하였다.
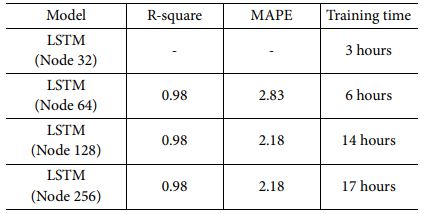
Table 8은 LSTM 모델의 Node별 정확도 및 학습시간을 보여준다. Node 32의 경우, S11 예측 값 중 최소값이 Linear Scale 기준 음의 값을 가지게 되었는데, S11은 입력 신호 대비 반사되서 돌아온 신호의 세기 비율로 Linear Scale 기준 0에서 1사이의 값만 가질수 있다. 따라서 음의 값을 가진 것은 비정상적인 모델이 생성된 것이므로 의미있는 R-square값과 MAPE 값을 계산할 수 없었다. LSTM 모델의 경우 학습시간이 최대 17시간으로 학습시간이 매우 긴 것이 특징이며 MAPE 값이 가장 좋은 성능 기준 2.18로 머신러닝 모델 중 가장 좋은 성능을 보여준 KNN 모델의 5.38보다 우수한 성능을 보여주었다. LSTM 모델의 경우 Node 수가 증가할수록 MAPE 성능이 개선되었으나 Node 256에서 성능 향상이 없으므로 최적 Node수는 128로 판단된다.
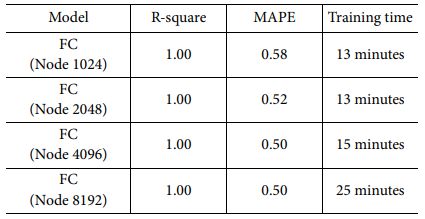
Table 9는 Fully-Connected 모델의 Node별 정확도 및 학습시간을 보여준다. 학습시간이 Node수가 가장 큰 8192 경우에도 25분으로 수초 수준인 머신러닝 모델들 보다는 느리지만 최대 17시간이 걸리는 LSTM 모델에 비하면 매우 빠르고 R-square 값과 MAPE 값도 최고 성능 모델 기준 각각 1.00, 0.50으로 머신러닝이나 LSTM 모델과 비교할 때 성능이 가장 우수한 것을 확인하였다. Node수 8192에서는 증가한 학습시간 대비 성능개선이 이루어지지 않아 Node수가 4096일 때가 최적임을 확인하였다.
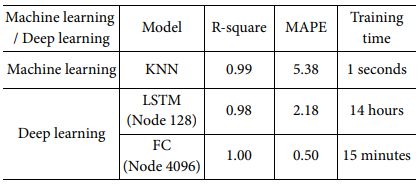
Table 10은 머신러닝 및 딥러닝별 최적 모델의 정확도 및 학습시간을 비교한 것으로, 학습시간은 머신러닝인 KNN 모델이 가장 빠르고, 성능은 딥러닝 Fully-Connected 모델 Node수 4096인 경우가 가장 우수함을 확인할 수 있었다.
Fully-Connected 모델의 학습시간은 KNN 모델보다 느리기는 하나 15분으로 충분히 빠르고 한 번 학습한 모델은 저장해 두었다가 빠르게 불러올 수 있으므로 크게 문제되지 않는다. 사용한 4 종류의 머신러닝 모델과 2 종류의 딥러닝 모델 중 R-sqaure 및 MAPE 기준 Ku-band용 Cross-dipole CA 전파 흡수 구조 전파 흡수 성능을 가장 정확하게 예측할 수 있는 회귀 모델은 Fully-Connected 딥러닝 모델임을 확인하였다.
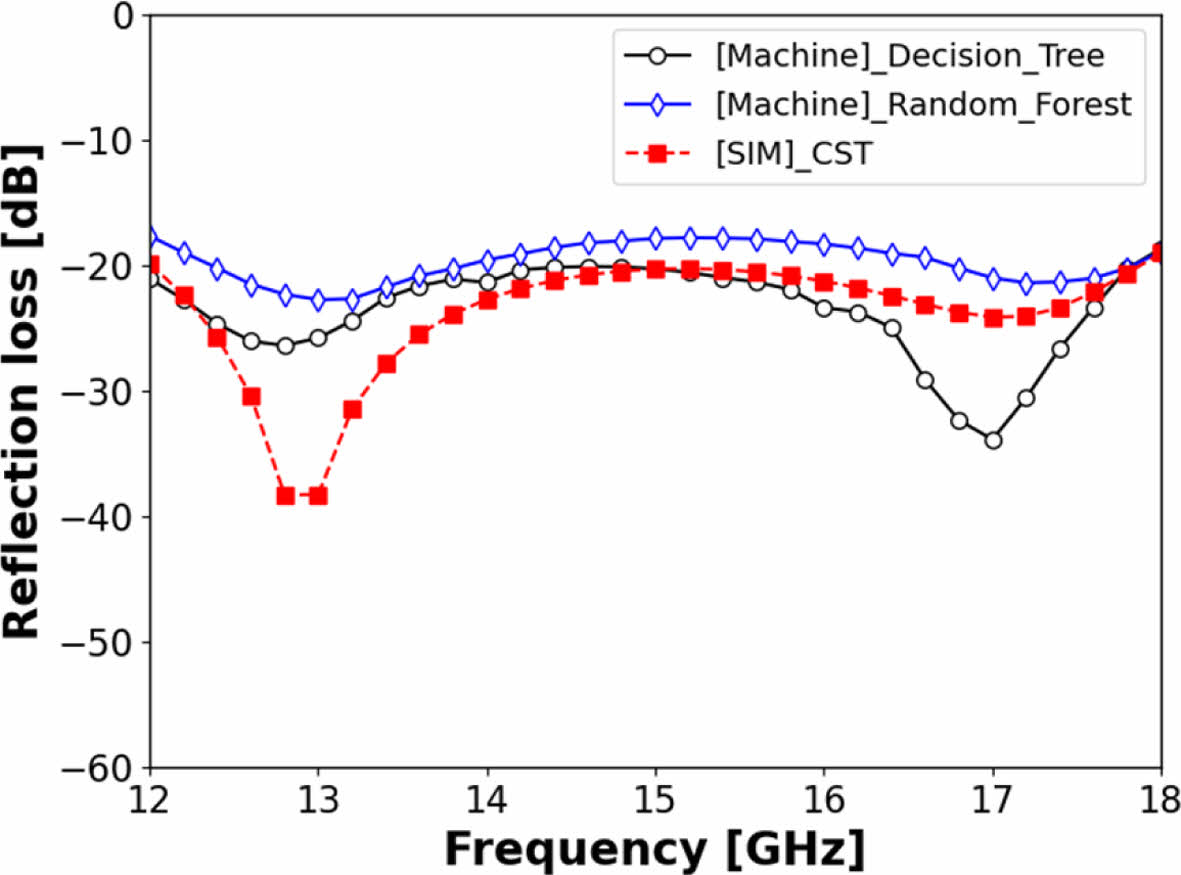
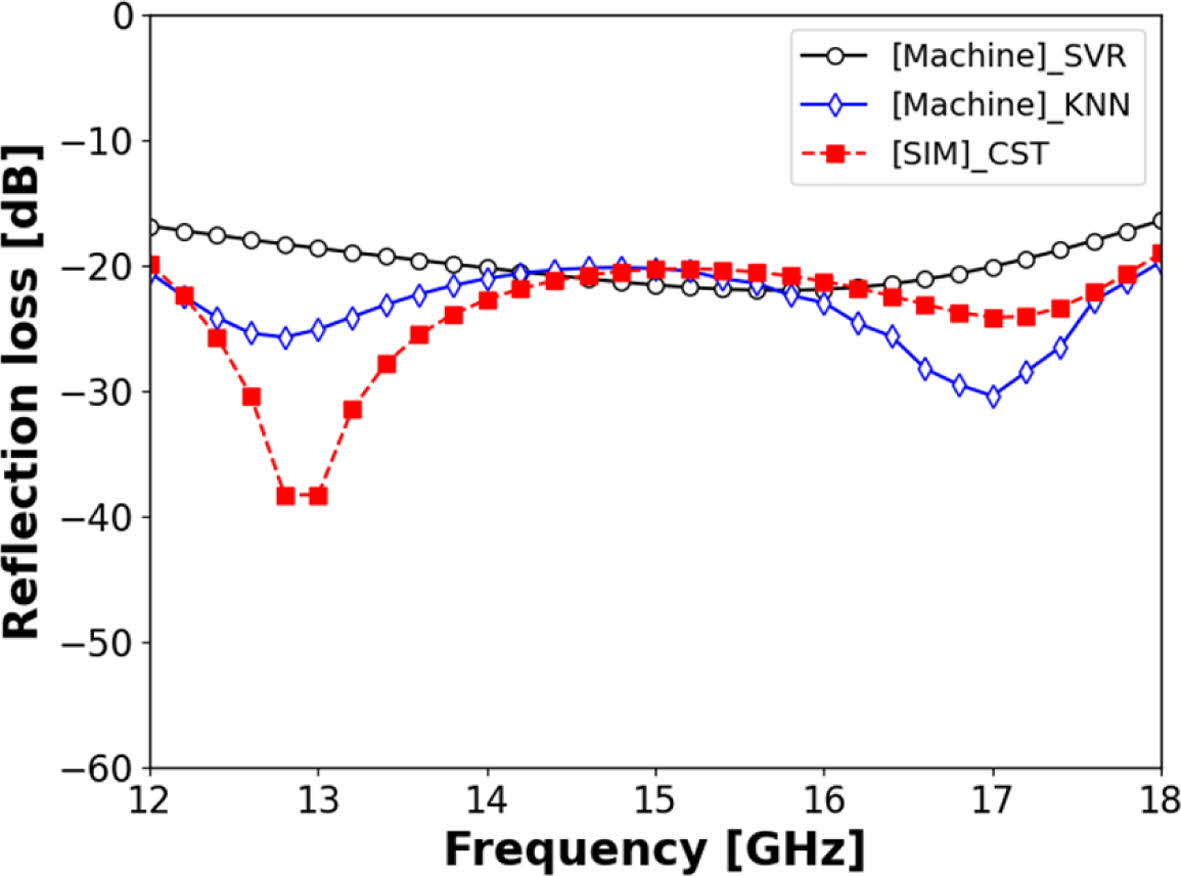
R-sqaure 및 MAPE 값으로 학습 모델에 검증용 Data 적용시 모델 정확도를 확인할 수 있었으나 Ku-band 대역에서 우수한 전파 흡수 성능을 보여주는 설계 변수 확보가 가능한지 확인하기 위해 CST의 Trust-Region Optimizer를 이용해서 얻은 Ku-band 전 주파수에서 최소 -19 dB 이상의 전파 흡수 성능을 보여주는 최적 설계 변수에서 모델별 전파 흡수 성능(S11) 예측 결과와 그 때 CST 해석 값을 비교하였다. 해당 case에서 사용한 설계 변수 값은 D 값 8.0, XD 값 0.68, WX 값 0.25이다. Fig. 8, 9는 머신러닝 모델에 해당 패턴 설계 변수값을 적용하였을 때 모델의 S11 예측 결과와 CST 해석 결과를 비교한 것이다. 머신러닝 모델 중에서는 KNN이 공진 Peak 점에서 세기의 차이는 있으나 공진 Peak 주파수가 유사하고 전반적으로 CST 해석결과와 가장 일치하는 결과를 보여주었다.
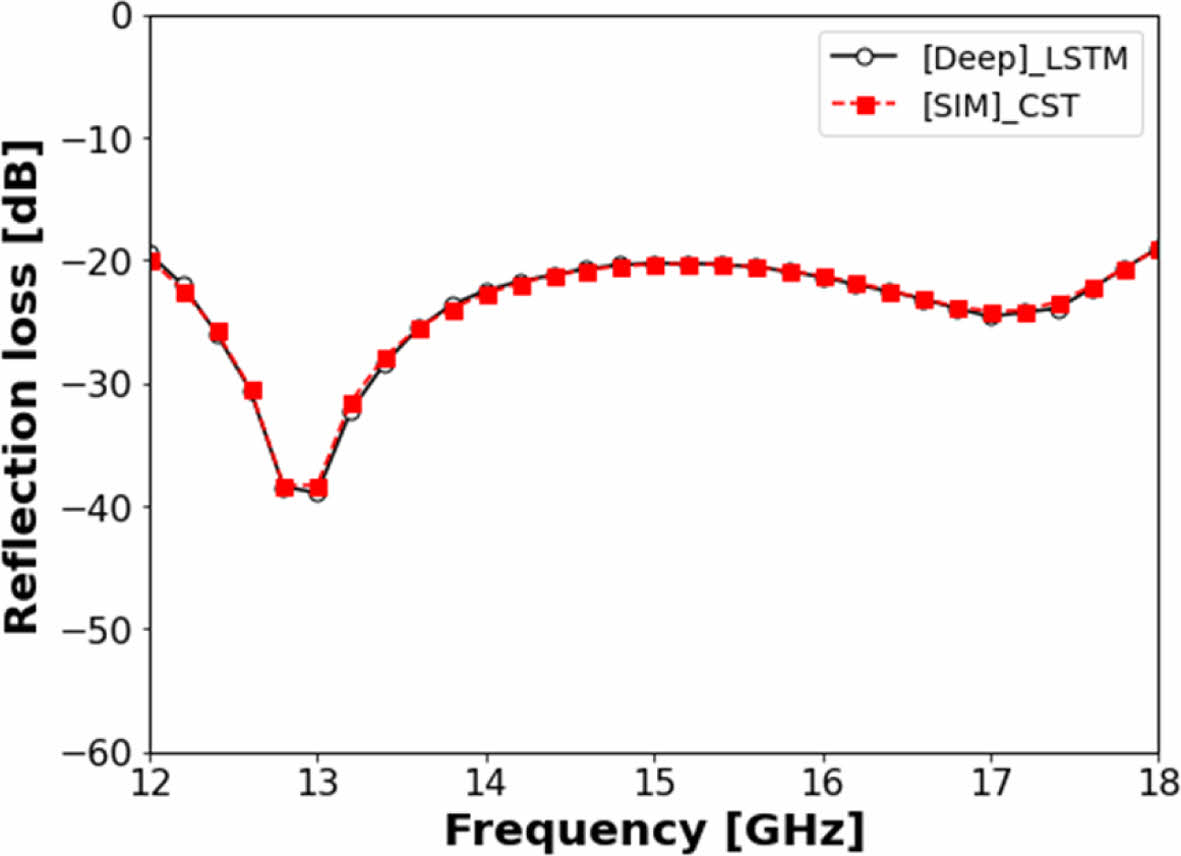
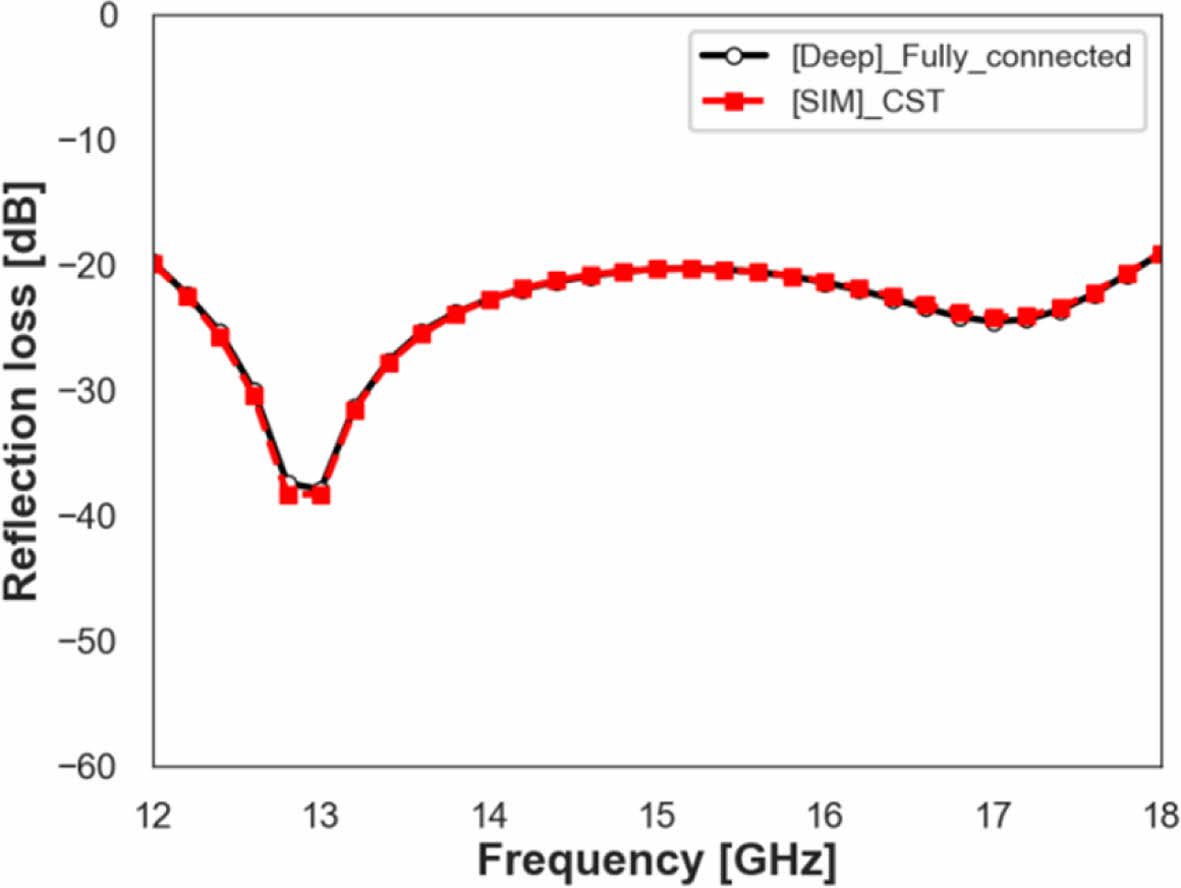
Fig. 10, 11은 LSTM 모델과 Fully-Connected 모델에 해당 패턴 설계 변수값을 적용하였을 때 전파 흡수 성능 예측 결과와 CST 해석 결과를 비교한 것으로, 두 모델 모두 예측 결과와 CST 해석 결과가 일치하는 것을 확인하였다. 해당 설계 변수(D = 8.0, XD = 0.68, WX = 0.25)는 학습 data에 존재하지 않는 값으로 딥러닝 모델 활용시 CST를 활용한 최적 설계와 동등한 수준의 설계를 별도의 전자기 해석없이 빠르게 도출할 수 있음을 확인하였다. R-square, MAPE 지표를 이용한 학습 정확도와 학습 모델을 이용한 전파 흡수 성능 예측값-CST 해석값 비교를 종합하였을 때, 사용한 4 종류의 머신러닝 모델과 2 종류의 딥러닝 모델 중 Fully-Connected 모델이 본 논문에서 사용한 Ku-band Cross-dipole CA 전파 흡수 구조 성능 예측용 회귀에 가장 적합한 모델임을 확인하였다.
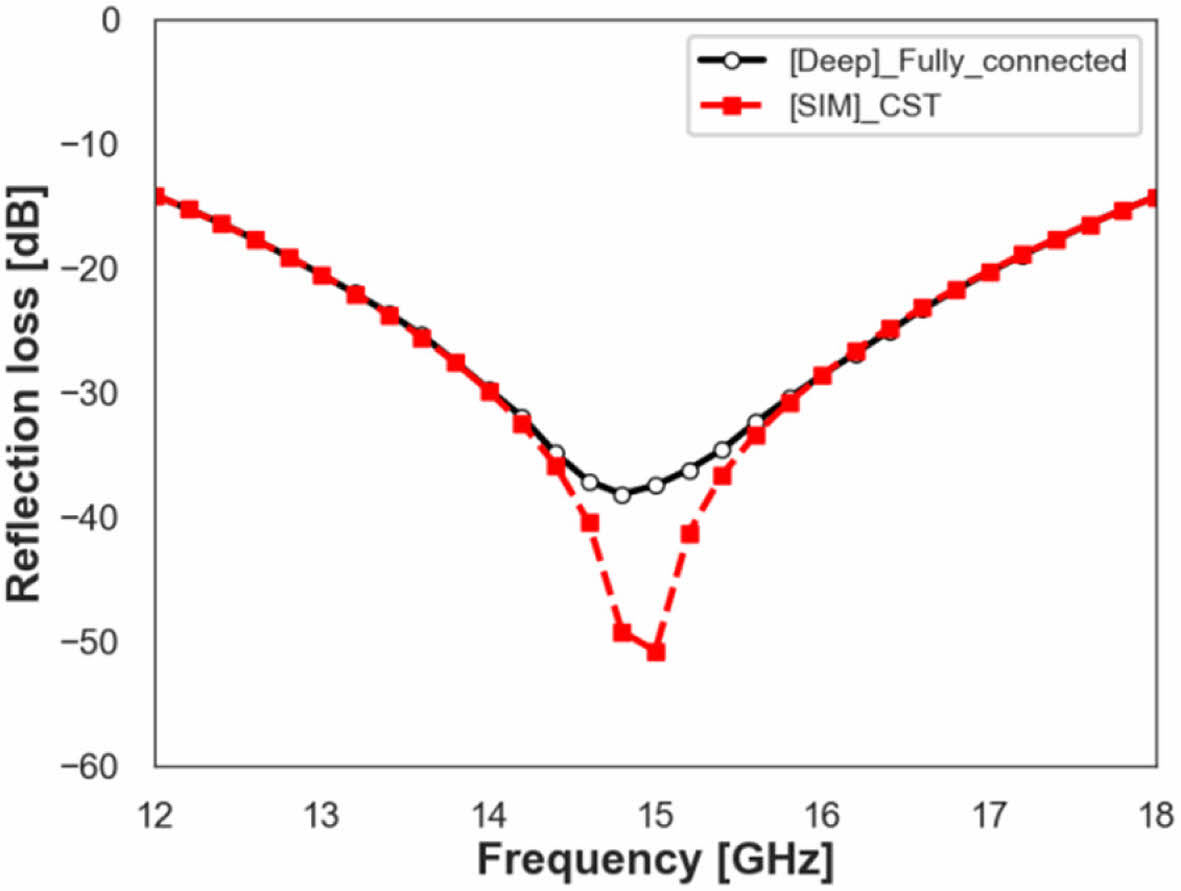
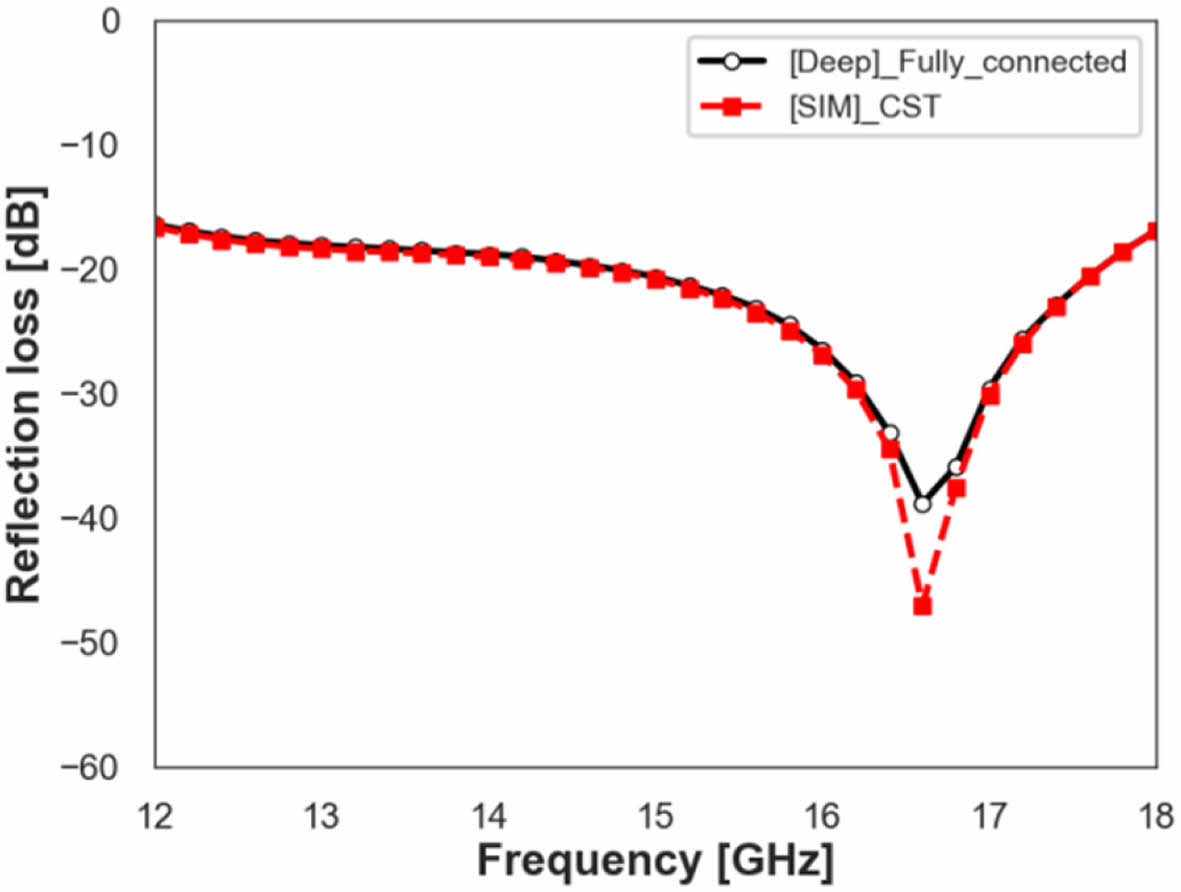
Fully-Connected 모델의 활용을 위해서 단일 주파수 대역에서 최적의 전파 흡수 성능을 보여주는 전파 흡수 구조 설계가 가능한지 확인해 보았다. Fig. 12, 13은 해당 모델을 활용해서 각각 15 GHz, 16.5 GHz에서 최적의 전파 흡수 성능을 보여주는 패턴 형상 값을 찾고, 해당 패턴 형상에서 모델을 이용해서 얻은 전파 흡수 성능 예측 결과와 CST 해석 결과를 비교한 것이다. 15 GHz 최적 설계 형상은 D 값 7.8, XD 값 0.7, WX 값 0.2이고, 16.5 GHz 최적 설계 형상은 D 값 7.8, XD 값 0.76, WX 값 0.2이다. Fig. 12, 13에서 볼 수 있듯 Peak 지점의 세기에서는 약간의 차이가 있으나 그 경향성 및 공진주파수는 정확히 예측이 가능한 것을 확인할 수 있었다.
|
Fig. 1 CA Radar absorbing structure |
|
Fig. 2 Resistive pattern design variables |
|
Fig. 3 Boundary condition |
|
Fig. 4 D, XD, WX design variable data distribution (left : training data, right : test data) |
|
Fig. 5 Data format |
|
Fig. 6 LSTM mode |
|
Fig. 7 Fully-Connected model |
|
Fig. 8 Decision Tree, Random Forest model, and CST simulation result at the Ku-band optimized design |
|
Fig. 9 SVR, KNN model, and CST simulation result at the Kuband optimized design |
|
Fig. 10 LSTM model, and CST simulation result at the Ku-band optimized design |
|
Fig. 11 Fully-Connected model, and CST simulation result at the Ku-band optimized design |
|
Fig. 12 Fully-Connected model, and CST simulation result at the single-frequency (15 GHz) optimized design |
|
Fig. 13 Fully-Connected model, and CST simulation result at the single-frequency (16.5 GHz) optimized design |


본 논문에서는 머신러닝 및 딥러닝 모델을 이용한 Ku 밴드 CA 전파 흡수 구조 설계 방법을 제시하고 머신러닝 및 딥러닝 모델별 성능을 비교하였다. 그 결과 가장 성능이 좋은 Fully-Connected 딥 러닝 모델 기준 R-square 값 1.00, MAPE 0.50 수준의 예측 모델을 구현할 수 있었으며 CST의 Trust-Region 최적화 기법을 통해 얻은 최적 패턴 형상을 예측모델에 적용하였을 때 딥러닝 모델을 통해 예측한 값과 CST 해석결과가 일치함을 확인하였다. 그 외 단일 주파수에서 최적의 전파 흡수 성능을 보여주는 전파 흡수 구조 패턴 설계 값을 모델을 이용해서 찾고, 해당 패턴 설계 값에서 성능 예측에도 높은 정확도를 확보가 가능함을 확인하였다. 해당 모델을 CA 전파 흡수 구조 주기성 패턴 설계에 적용한다면 전파 흡수 주파수 대역에 따른 재설계 및 최적화 시간을 크게 감소시켜 설계 효율성 제고가 가능할 것으로 판단된다. 본 논문에서는 Fully-Connected 딥러닝 모델 기준 3개의 설계 변수를 사용하여 Cross-dipole CA 전파 흡수 구조의 패턴 형상별 전파 흡수 성능 예측 회귀 모델을 작성하여 설계에 활용 가능함을 확인하였다. Fully-Connected 딥러닝 회귀 모델의 경우 최대 사용 가능 변수 개수 제한이 존재하지 않으므로 본 논문에서 제시된 바와 같이 전파 흡수 구조 설계에 사용하는 설계 변수를 명확하게 정의할 수 있고 충분한 량의 학습 Data 확보가 가능하다면 3개 이상의 설계 변수를 사용하는 CA 전파 흡수 구조나 다른 방식의 전파 흡수 구조 설계에도 적용이 가능할 것으로 판단된다.
본 연구는 한국재료연구원에서 지원하는 창의Seed 사업 연구과제(PNK 8610)로 수행된 것이며, 지원에 대해 진심으로 감사드립니다.
- 1. Park, B., Ryu, S.H., Kwon, S.J., Kim, S., and Lee, S.B., “A Conductive-grid based EMI Shielding Composite Film with a High Heat Dissipation Characteristic,” Composite Research, Vol. 35, 2022, pp. 175-181.
-
- 2. Choi, K.S., Sim, D., Choi, W., Shin, J.H., and Nam, Y.W., “Ultra-high Temperature EM Wave Absorption Behavior for Ceramic/Sendust-aluminosilicate Composite in X-band,” Composite Research, Vol. 35, 2022, pp. 201-205.
-
- 3. Vinoy, K.J., and Jha, R.M., “Radar Absorbing Materials from Theory to Design and Characteristics,” Alphen aan den Rijn, The Netherlands: Kluwer, 1996.
-
- 4. Salisbury, W.W., “Absorbent Body for Electromagnetic Waves,” U.S. Patent 2,599,944, 1952.
-
- 5. Jang, H.K., Kim, J., Park, J.S., Moon, J.B., Oh, J., Lee, W.K., and Kang, M.G., “Synthesis and Characterization of a Conductive Polymer Blend Based on PEDOT:PSS and Its Electromagnetic Applications,” Polymers, Vol. 14, 2022, 393.
-
- 6. Liu, T., and Kim, S.-S., “Design of Wide-bandwidth Electromagnetic Wave Absorbers Using the Inductance and Capacitance of a Square Loop-frequency Selective Surface Calculated from an Equivalent Circuit Model,” Optics Communications, Vol. 359, 2016, pp. 372-377.
-
- 7. Kim, J., Jang, H.K., Oh, J., and Park, J., “A Rational Design Procedure for Absorbers of Square-Loop-Shaped Resistive Frequency Selective Surface Placed on Glass/Epoxy Laminate,” IEEE Transactions on Electromagnetic Compatibility, Vol. 65, No. 1, 2023, pp. 104-113.
-
- 8. Lee, W.-J., Lee, J.-W., and Kim, C.-G., “Characteristics of an Electromagnetic Wave Absorbing Composite Structure with a Conducting Polymer Electromagnetic Bandgap (EBG) in the X-band,” Composites Science and Technology, Vol. 68, No. 12, 2008, pp. 2485-2489.
-
- 9. Choi, W.-H., Kim, J.-B., Shin, J.-H., Song, T.-H., Lee, W.-J., Lee, Y.-S., and Kim, C.-G., “Circuit-analog (CA) Type of Radar Absorbing Composite Leading-edge for Wing-shaped Structure in X-band: Practical Approach from Design to Fabrication,” Composites Science and Technology, Vol. 105, 2014, pp. 96-101.
-
- 10. Choi, W.-H., Kim, J.B., Shin, J.H., Song, T.H., Lee, W.J., Joo, Y.S., and Kim, C.G., “Design of Circuit-analog (CA) Absorber and Application to the Leading Edge of a Wing-shaped Structure,” IEEE Transactions on Electromagnetic Compatibility, Vol. 56, No. 3, 2014, pp. 599-607.
-
- 11. Choi, W.-H., Kwak, B.S., Kewon, J.H., and Nam, Y.W., “Microwave Absorbing Structure Using Periodic Pattern Coated Fabric,” Composite Structures, Vol. 238, 2020, 111953.
-
- 12. Jang, H.K., Shin, J.H., Kim, C.G., Shin, S.H., and Kim, J., “Design and Fabrication of Semi-cylindrical Radar Absorbing Structure using Fiber-reinforced Composites,” Composite Research, Vol. 23, 2010, pp. 17-23.
-
- 13. Wu, B., Wang, G., Liu, K., Hu, G., and Xu, H.X., “Equivalent-circuit-intervened Deep Learning Metasurface,” Materials & Design, Vol. 218, 2022, pp. 17-23.
-
- 14. On, H.I., Jeong, L., Jung, M., Kang, D.J., Park, J.H., and Lee, H.J., “Optimal Design of Microwave Absorber Using Novel Variational Autoencoder from a Latent Space Search Strategy,” Materials & Design, Vol. 212, 2021, 110266.
-
- 15. Liu, H.T., Cheng, H.F., Chu, Z.Y., and Zhang, D.Y., “Absorbing Properties of Frequency Selective Surface Absorbers with Cross-shaped Resistive Patches,” Materials & Design, Vol. 28, No. 7, 2007, pp. 2166-2171.
-
- 16. Lee, I.J., Choi, S.H., Joo, I.O., Jeon, J.W., Cha, J.H., and Ahn, J.Y., “Technical Trends on Low-Altitude Drone Detection Technology for Countering Illegal Drones,” Electronics and Telecommunications Trends, Vol. 37, 2022, pp. 10-20.
-
- 17. Costa, F., Monorchio, A., and Manara, G., “An Equivalent Circuit Model of Frequency Selective Surfaces Embedded within Dielectric Layers,” in Proc. IEEE Antennas Propag. Soc. Int. Symp., 2009, pp. 1-4.
-
- 18. Goodfellow, I., Bengio, Y., and Courville, A., “Deep Learning,” USA: MIT Press, 2016.
 This Article
This Article
-
2023; 36(2): 92-100
Published on Apr 30, 2023
- 10.7234/composres.2023.36.2.092
- Received on Feb 27, 2023
- Revised on Mar 15, 2023
- Accepted on Mar 27, 2023
Services
Shared
Correspondence to
- Jin Bong Kim
-
Composites Research Division, Korea Institute of Materials Science (KIMS), Korea
- E-mail: jbkim@kims.re.kr
Gangnam Mirae Tower, Suite 601, 174 Saimdang-ro, Seocho-gu, Seoul 06627, South Korea
Tel: +82-2-598-1550 Fax: +82-2-598-1557 E-mail: composites@kscm.re.kr